MQ异步事务业务的设计
MQ异步事务业务的设计
前言
在非常非常多的系统中都会存在两阶段或以上业务强绑定关系的场景,比如用户购买商品成功后,累加用户的积分。在开发人眼中,以上的动作是:
if用户购买商品成功 ,return商品库存扣除if用户控制库存扣除,return累加该商品的积分
当然了,这只是一个不显著的例子。我想表明的是,在业务系统设计中所逃不开的一点:两个功能点高度耦合,但是需要保存一致事务。
在我的开发日常中,发现小的系统很容易解决这点:单点架构仅通过一个事务控制即可。而大系统则由于服务中心化,分布式、AOP等等因素的影响使得这一问题的考虑需逐渐加深。
所以为了针对:如何设计功能不耦合,但是事务耦合的需求 这一要点,记录一篇思路上的整合规划;
按照惯例,将我们的文章放在以下一个简单例子的背景下:
简单例子
这样关系的需求有太多太多,比如前文提到的商城中的用户购买后加积分、功能触发成功后,消息推送、xxxx后,进行xxxx等等。
所以还是用最简单的案例:
你接到了一个需求,需要在用户购买一件商品成功后,将该商品的积分累加到用户信息上。
需求分析
案例中的需求很简单:
- 商品下单服务
- 积分累加服务
快速实现
现在你拿到了需求,绕绕头,这不就是一个很简单的订单业务,下单成功把用户的积分加上就好了吗,因此你预估了以下任务的工时:
- 用户下单功能
- 用户累加积分方法
而后在你的操作下,你实现了如下的方法:
try{
//1、用户下单成功,扣除库存
//2、累加该商品积分
//3、调用支付接口
}catch{
//事务回滚
//对账
}
采用一条链路上实现所有节点功能的方式,一个失败全部回滚;
你看着你的"杰作",预估了一下线上的流量,于是自信的开始版本发布。
开始异步
终有一天,客户发起工单举报你:为什么我点击付款经常会卡死?
这时你意识到了,单机的服务终于是顶不住我们公司的流量了;
于是你向领导申请经费,购置了一台更强大的服务器,并且将下单动作、累加积分动作、实际支付动作拆成了三个服务,彼此之间使用mq、rpc通讯。
这时系统的架构为成了我们常见的异步业务系统:
于是乎你意识到了一个问题,坏了,总想着流量分流竟然忘记分布式事务问题,于是你开始了针对我们本次的主题:MQ中异步事务的设计 进行了一系列的解读。
异步事务
你仔细考虑了两个功能在事务中会有如下的排列组合(以下功能A代指下单服务,功能B代指积分服务):
第一种
- 开启本地事务
- 功能A完成
- 投递MQ到功能B
- 提交本地事务
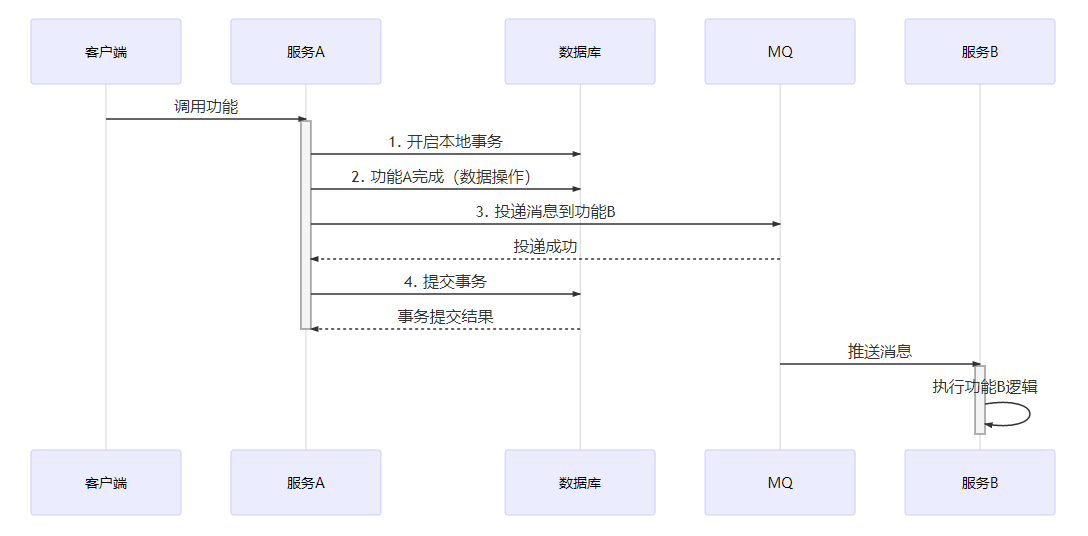
很像一个小白刚入行时所采用的方案,你赶紧摇摇头,举列了这一种的异常错误:
- 第三步投递MQ异常,导致正常下单的服务A也更着异常进行回滚,直接影响了服务A的功能。而服务B的积分累加功能只是服务A的附加项,可以后续通过数据干预进行被动修复
- 第四步提交事务异常,导致业务消息正常投递服务B,功能B累加积分正常执行。
第二种
你的思路出现了惯性思考,既然事务提交会与消息投递互相干预,那么我将消息投递放在最后不就好了
- 开启本地事务
- 功能A完成
- 提交本地事务
- 投递MQ到功能B

写到第四步的时候,你突然惊醒,🙄这不会第一种一样吗,也会出现如下异常错误:
- 第四步投递MQ异常,导致功能A成功执行,功能B却失败了。
不过,你发现了服务B的数据可以采用一个定时功能进行数据对账,而被动的修复这种异常;但是!你觉得这根本不是一种健壮的程序,但是你将对账的这种思路加之进行了优化,于是诞生了第三种:
第三种
你发现只要你可以在投递的过程中就完成"对账",那么就可以保证这个消息与事务间不再干预
- 开启本地事务
- 功能A完成
- 服务A的表
msg_record中新增一条数据,状态为0(待投递),并且返回主键id - 提交本地事务
- 开启确认功能本地事务
- 判断功能A是否成功结束,弹出
id对应的msg_record的数据,修改状态为1(投递成功) - 投递MQ到功能B
- 提交确认功能本地事务
- 开启一个定时任务,扫描出
msg_record表中流程中断的数据,比如状态为0,但是时间超时的未成功投递MQ的数据。 进行相应的重复投递操作(20秒间隔/内循环等等),最终实现本地对投递功能与功能A的“对账”确认机制
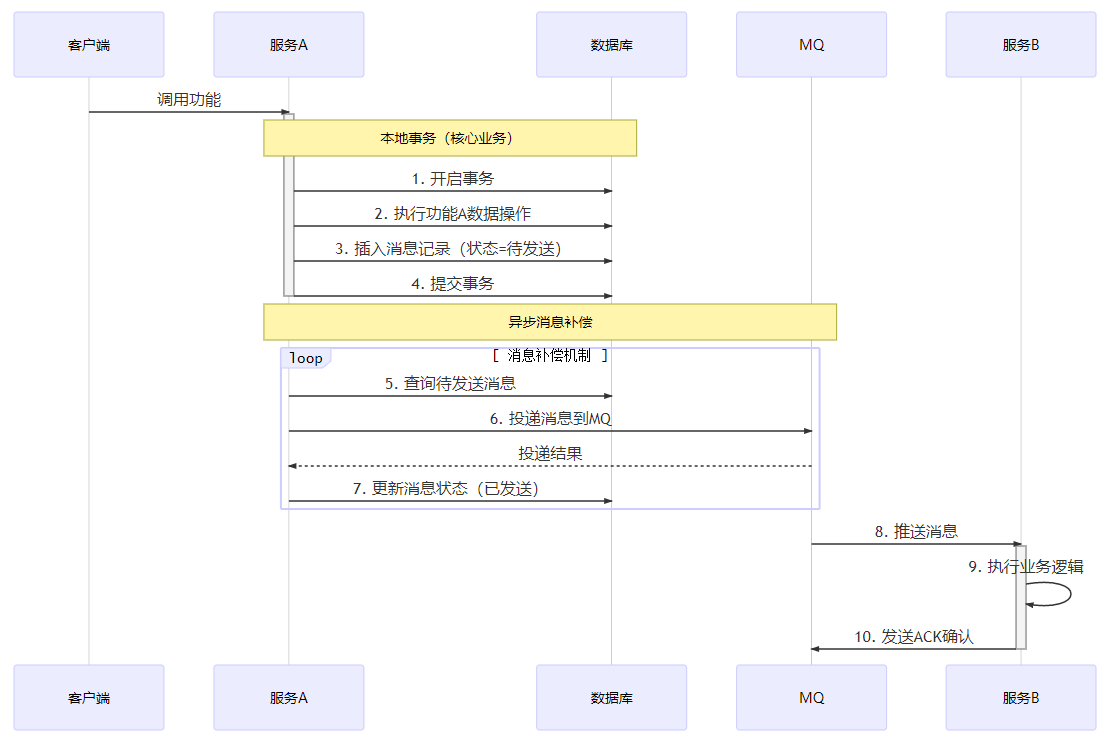
这次你仔细检查了流程,感觉没有漏洞并且进行了十足的测试。这下你满意的将这次关于事务与MQ的代码逻辑版本上线,并且在一定时间内稳定运行;
不过随着用户量的增加,系统服务的增加,你发现这一段代码面临了两个问题:
- 由服务A本地“对账”,增加机器的额外开销,数据量大了之后是一笔不可忽视的费用
- 其他同事想借用你的这套流程,发现每次copy过来还需要手动修改,并不可以作为一个通用的处理方案
于是你想了第四种对策进行优化
第四种
你想了想,只要将这套对账的逻辑单独开立一个系统服务,作为中间服务进行投递与判断的实际动作,所有的问题都可以迎刃而解了
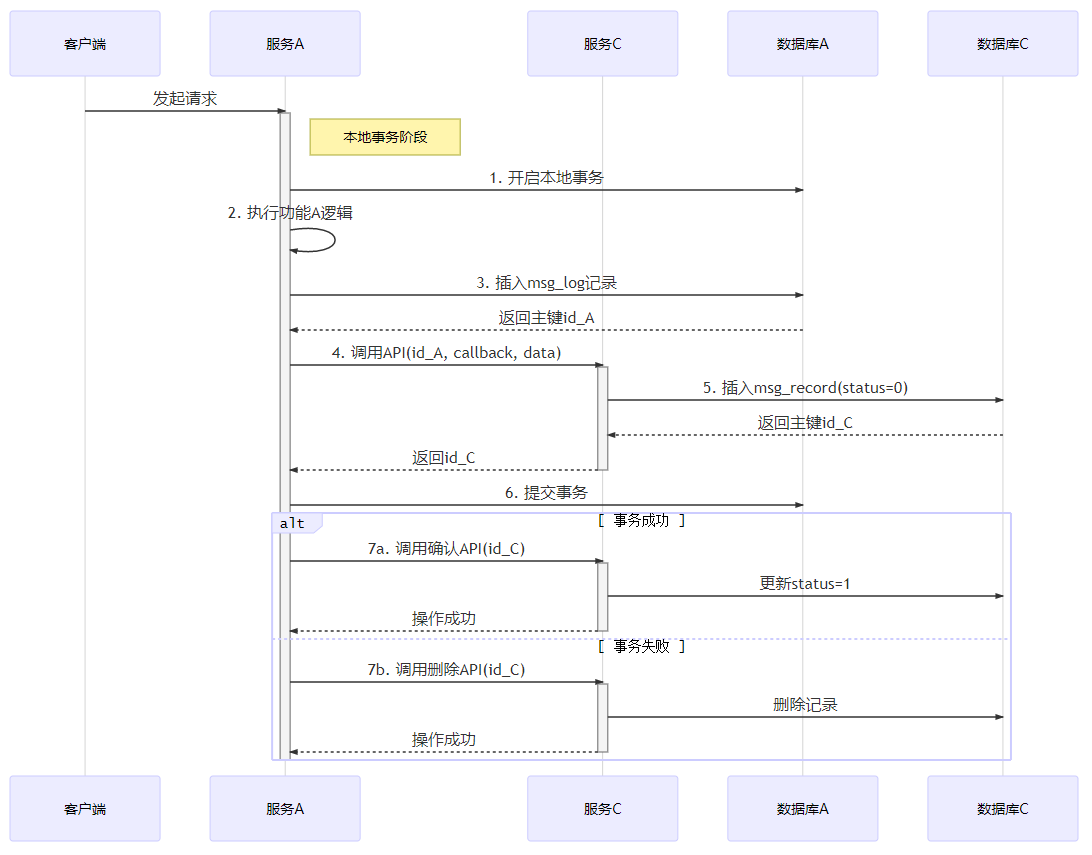
为了达到这个目标你设计了这两张表:
服务A_msg_log
- id 主键
- business_id 业务id
- business_type 业务类型
msg_record
- id 主键
- msg_log_id 服务A_msg_log的id
- body 消息
- msg_log_url 业务方回调接口
- status 状态
- msg 状态的实时消息
并且设计了如下的流程步骤(以下消息事务确认系统简称服务C)
- 开启本地事务
- 功能A完成
- 服务A的msg_log插入一条记录,返回id主键
- 调用服务C的api,入参为本地消息表的主键id,回调接口,消息体...
- 服务C接收数据,插入本次的业务事务数据到
msg_record表中status为0(待发送),并且返回主键id给服务A - 提交本地事务
- 如果上述操作全成功,则使用步骤5中返回的主键id,调用服务C确认投递发送的api;如果上述操作失败事务回滚,则使用主键id,提醒服务C删除
msg_record中的数据 - 操作成功情况:服务C调用数据中的回调接口,由服务A回调接口将实际消息投递到服务B中
总结
到此完结,简而描述是涉及事务与消息投递业务中,如何确保数据一致性的问题;非常简单,本文中对于服务中的一些细节并没有提及。比如服务C中回调接口的应用,如果服务B的累加积分功能发生失败的情况,如果服务C的功能发送失败等等等等...
因为思考的过程很好玩,这些处理留白我觉得自行挖掘更好玩;