一次Netty通讯内存泄漏经验
一次Netty内存泄漏导致OOM的排查经验
背景: 在一个设备通讯项目中,总是会周期性的发生重启。但在项目运行中,又没有任何异常,在排除了机器、代码、网络等因素问题后,则开始了内存、代码层面的排查工作。
Dump文件
首先先将最近的一次发生重启动作前的JVM内存dump文件下载下来:
JVM启动命令增加两个参数:
-XX:+HeapDumpOnOutOfMemoryError
-XX:HeapDumpPath=/home/app/dumps/
手动执行指令,直接生成当前JVM的dump文件:
jmap -dump:format=b,file=/home/app/testdump.hprof 6218
将生成下来的文件放到dump解析软件中
强力推荐使用JProfiler
https://www.ej-technologies.com/
原因:
- 实时监控开销费小,注入式采集
- 功能强大齐全
- UI简洁、分类清晰
- ...
不过 JProfiler 目前我没找到其免费破解版,所以当前14天使用的一次性软件刚刚好;
然后可以拿到如下图示:
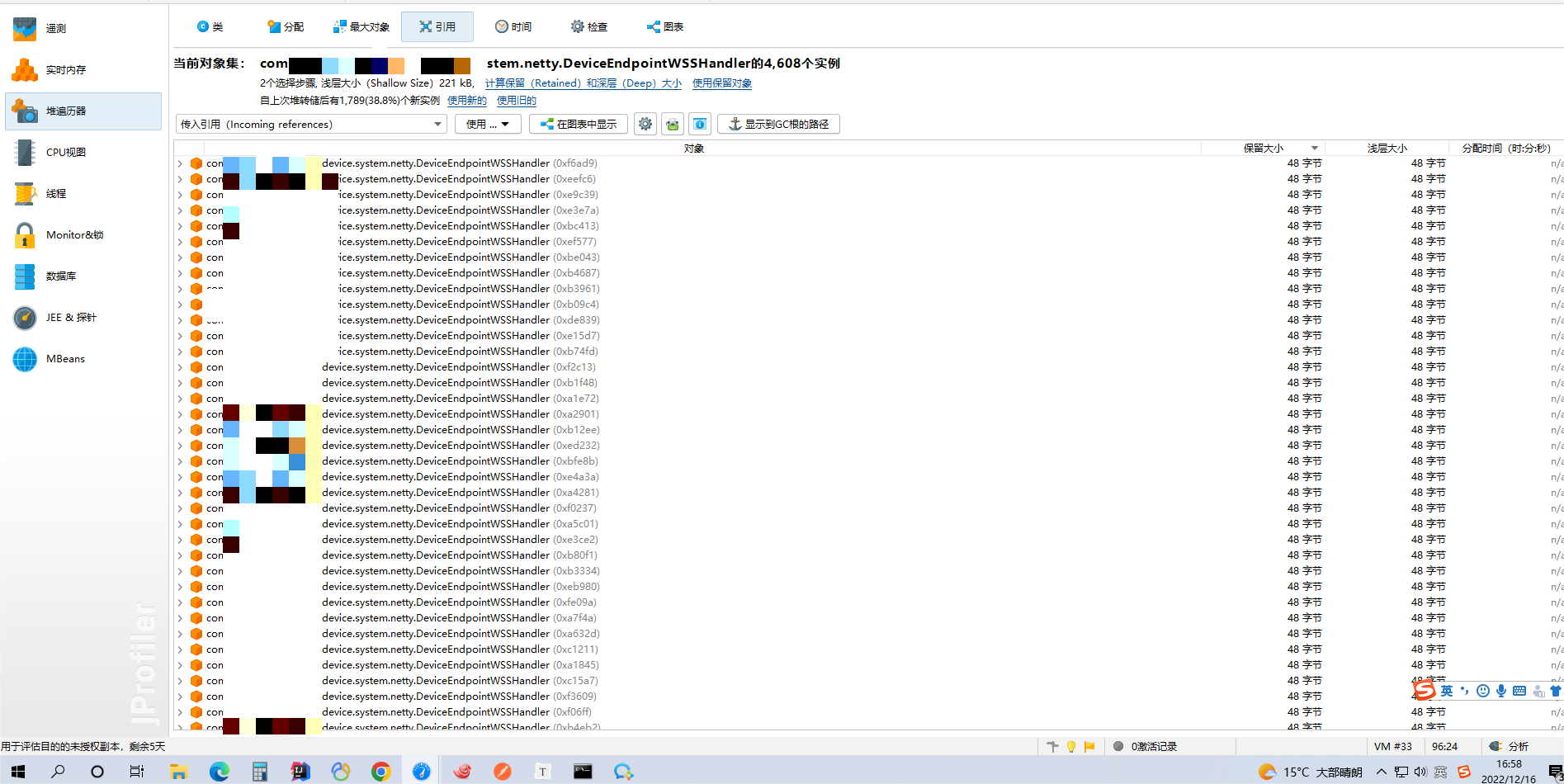

项目中每个存货在内存中类的个数、占用大小、地址code码等
引用界面,更是能追溯到该类的上行创建以及下行引用的相关类和方法
根据dump分析,我们很直观的发现重启前的虚拟机内存已经达到了设置内存的99%,所以导致docker部署的Java项目异常停止,由docker容器自动触发重启机制。
排查JVM内存
在知道了是内存占满导致程序重启后,则需分析应用是哪部分内存空间导致虚拟机占满。
进行以下三步走:
进入程序中,拿到进程pid
Jar包运行: netstat -anp | grep 程序端口号 Docker内程序: docker ps -a 拿到应用containerid 进入容器: docker exec -it containerId /bin/sh 或 docker exec -it containerId bash 查看当前容器的pid 容器内: jps 内存监控 jstat -gcutil pid 时间[毫秒]分析内存结构

属性 含义 S0 Heap上的 Survivor space 0 区已使用空间的百分比 S1 新生代存货1空间 E 新生代伊甸园空间 O 老年代空间 M 元空间容量 CCS YGC Young GC次数 YCCT Young GC 所用时间 FGC Full GC次数 FGCT Full GC 所用时间 GCT GC操作总耗时 要了解虚拟机的稳定,则需要重点关注,老年代容量、Full GC次数、Full GC时间、Young GC时间
打印日志,等待重启
将 jstat -gcutil pid 时间[毫秒] 输出,直到容器重启
如预料中的一样,FGC随时间的增加愈加频繁,最终M占用99,服务重启。
所以内存占用的原因是频繁进行Full GC,而Full GC能频繁的进行最无非就是内存内漏或对象占满。
Netty 排查
打印Netty内存日志
public static void main(String[] args) {
Field field = ReflectionUtils.findField(PlatformDependent.class, "DIRECT_MEMORY_COUNTER");
field.setAccessible(true);
directMem = (AtomicLong) field.get(PlatformDependent.class);
}
按秒打印内存大小,在建立连接后,重复发送消息动作。
检查内存是否会在没有操作时上下波动。
但是发现内存正常
Netty监控机制
在检查代码无死循环、迭代、多重循环DB等代码灾难级错误后,则对netty连接通讯进行排查。
好在,官方有提供给我们 netty 自带内存泄漏监控机制;

将开启检测的参数加在JVM启动项中。
进行连接Netty操作
在多次进行断开,连接,发送消息操作后,抛出错误

我们的老伙计ByteBuf他又又又报错了。
于是乎,去官方、社区等渠道去了解ByteBuf在Netty中是何种存在,又是为何发生Netty内存泄漏问题的大头总是他。
ByteBuf
在Netty中,ByteBuff类按有无使用池化操作分为两类:
一是非池化存储,如UnpooledHeapByteBuf、UnpooledDirectByteBuf等中间对象,每次在进行读写I/O操作时都会创建一个全新的对象,在内存中按照对象大小分配空间片;所以在频繁业务中由于分配问题,对回收性能都有一定的影响,但对于这种对象,可以由JVM全权处理,判断是否回收。也可以调用ByteBuf对象的回收方法,手动通知回收
二是池化存储,如pooledHeapByteBuf、pollAbstractByteBuf等对象,这种属于Netty在初始期会在内存中申请一片大空间,然后对于池化ByteBuf对象进行大空间内的二次分配;所以池化存储的对象隔离与JVM对空间片管理,由Netty直接性的进行判断是否回收;这种对象则必须进行手动处理引用计数,以此释放对象。
ByteBuf通过其引用计数下标为0,触发回收操作
而控制ByteBuf引用计数的方法,则是.release()和.retain()
泄漏原因分析
在了解了ByteBuf的两种存在模式后,则立马对项目内,有使用到Netty传过来的ByteBuf进行两次处理、转化、使用等业务代码块;
Netty连接是基于官方的Demo加工:
1、首先从连接入口:

官方定义,在进行一次消息处理后,将其引用减一
2、消息

通过断点,可以看到 不管FullHttpRequest或WebSocketFrame或其余从这里进入的对象,大多是池化的ByteBuf,所以我只要一路Debug,查看改msg的属性refCnt的计数值变化。
3、错误点

在处理关闭连接的分支操作中,发现莫名进行了两次**.retain**方法,并且下行链路中,并没有进行其对应的 .release方法,导致在整个业务链路走完后,没有释放出本次连接对象;
并且由于一次连接关闭,所发的消息体只是短短的一个字段,占用很小很小,大概1KB甚至更小。
但由于设备的不稳定性,某些设备可能在频繁的重复进行断开、连接操作,内存也非常不稳定的不知何时满。
所以在测试的时候,没有发现出这个BUG。
ByteBuf特性注意点
计数器
ByteBuf通过继承AbstractReferenceCountedByteBuf类,实现了自带计数器的实现。
而调用其 .retain 和 .release 控制属性refCnt;
当为0时,触发释放,否则永远存留在池化空间中。
具体触发与实现,可见AbstractReferenceCountedByteBuf源码
注意点
- 当创建一份ByteBuf或Copy另一份ByteBuf时,计数器会初始化,并且随着创建,在代码中一定要有其对象配套的 release方法
- 如果使用decode()、retainedSlice(index, length)方法,创建出来的ByteBuf会共用同一个计数器
- 如果使用slice(), order(),创建的子类ByteBuf,没有子类计数器,使用的是父类计数器
- ...
总结
聊聊这类事故出现的主要原因**:在使用Demo前,未参透每个陌生方法的含义,以及方法调用与不调用对系统造成的影响**
在排查的工程中,也是初步的去深入接触了Netty的内存组成;
比如内存分配和回收管理的实现 PoolChunk
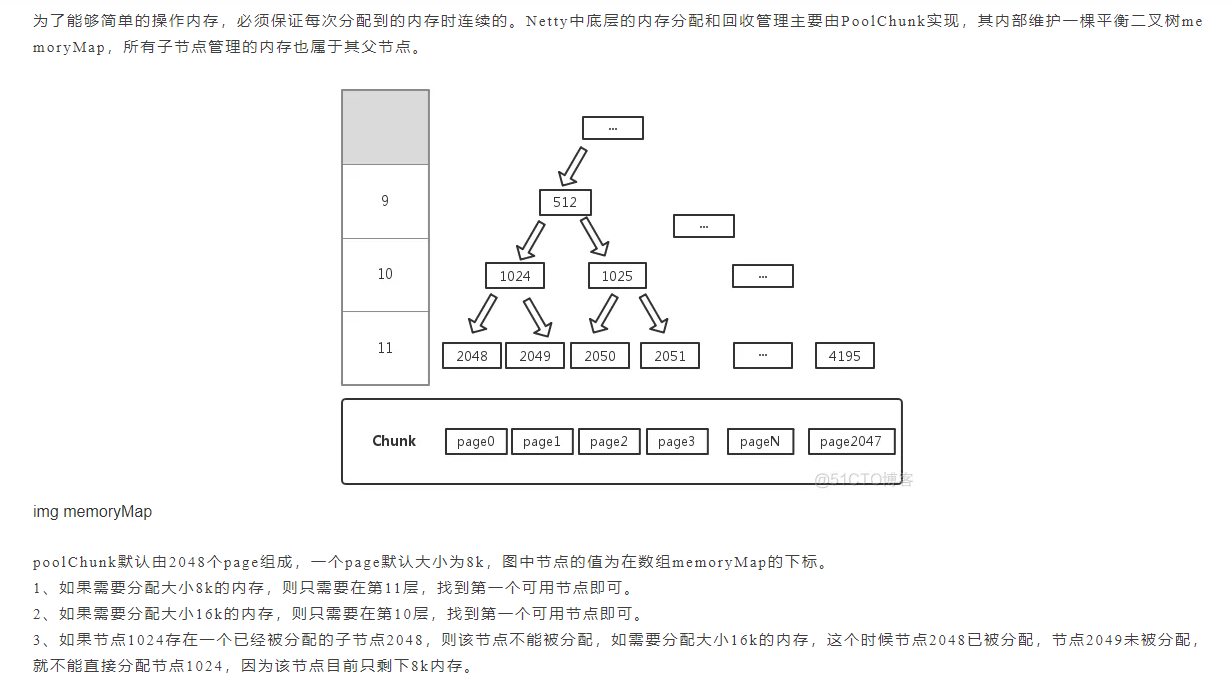
并且知道了Netty的几种隐藏排查内存问题的方法;
比如开启内存检测机制,测试时建议打开最高等级,因为他的抛错可以直接间接的去帮你优化一些对象的处理;
比如 通过反射的方式直接拿到Netty当前所使用的内存大小,然后打印出来
...