思考多线程事务场景
多线程事务场景方案
我们在考虑大批量数据的db业务中,除了常规逻辑上的思考如何通过Jdbc的批处理操作和参数去优化db,在这种需求的背景下不使用多线程处理永远是快不起来的;
由此本篇针对一个需求,模拟多线程下的处理方式和思考
需求背景
一个导入功能,Excel里有50w+数据。
很常见的导入功能,不常见的是这个Excel里有50W条数据,而且我们还需要支持一次性导入到系统中;
然后再是这个需求的各种附加项:
- 用户刷新页面,重复导入这份文档
- 只能支持数据全部导入,不支持部分失败
- 导入的数据需要按照文档数据有序
- 速度尽可能的快
- ....
开始讨论
附加项1
首先是附加项1:要点在于如何去确认这个文件已经在这个用户在被导入过,还在系统的处理的处理时间内;
思来思去,有且只有一个办法,文件的md5值;
不过文件这么大,难道还需要后台再接收文件之后,还拿它计算一次md5值吗?
所以必须由前端将文件分片,取文件的第一片作为本文件的md5值
见代码:
methods: {
calculateMD5(file) {
return new Promise((resolve, reject) => {
const fileReader = new FileReader()
const time = new Date().getTime()
const blobSlice = File.prototype.slice || File.prototype.mozSlice || File.prototype.webkitSlice
let currentChunk = 0
const chunkSize = 5 * 1024 * 1000
const chunks = Math.ceil(file.size / chunkSize)
const spark = new SparkMD5.ArrayBuffer()
//只计算第一片文件md5码
const chunkNumberMD5 = 1
loadNext()
fileReader.onload = e => {
spark.append(e.target.result)
if (currentChunk < chunkNumberMD5) {
loadNext()
} else {
const md5 = spark.end()
file.uniqueIdentifier = md5
console.log(`MD5计算完毕:${file.name} \nMD5:${md5} \n分片:${chunks} 大小:${file.size} 用时:${new Date().getTime() - time} ms`)
}
resolve();
}
fileReader.onerror = function () {
reject();
ElMessage.error(`文件${file.name}读取出错,请检查该文件`)
file.cancel()
}
function loadNext() {
const start = currentChunk * chunkSize
const end = ((start + chunkSize) >= file.size) ? file.size : start + chunkSize
fileReader.readAsArrayBuffer(blobSlice.call(file.file, start, end))
currentChunk++
}
});
}
}
不过缺点也很明显,如果文件内容不变,仅仅只是改变顺序的话我们无法判断这个文件是否被导入过;
所以还是把产品打死,改需求把
附加项234
2,3,4点也是本篇的标题,指的是在大数据量插入操作中,使用多线程将其顺序写入;
插入一个tip,在很久以前对于大数据写入业务,有个一个讨论分析:大数据量写入场景问题
因为多线程的优势,在我们将数据导入之后的动作,分批次的丢进子线程之后,客户要的速度问题也就迎刃而解了;
核心问题点在于如何去处理各个子线程中的事务提交,也就是附加项2;并且还需要考虑到各个子线程的事务提交顺序,也就是附加3。
先说结论:没有绝对的方案保证这种多线程事务可以做到又快,又有序还保证原子性;
事务管理
第一种
我们知道,Spring管理事务的颗粒是线程级别的,因此以下代码是无法作用于子线程中;
@Transactional
public void mainThread() {
for (int i = 0; i <= 10; i++) {
CompletableFuture.runAsync(() -> {
excelDao.save(null);
});
}
}
在子线程中,需要手动进行事务编排;
@Autowired
private PlatformTransactionManager platformTransactionManager;
public void mainThread() {
for (int i = 0; i <= 10; i++) {
CompletableFuture.runAsync(() -> {
TransactionStatus transaction = platformTransactionManager.getTransaction(new DefaultTransactionDefinition());
try {
excelDao.save(null);
platformTransactionManager.commit(transaction);
}catch (Exception e){
platformTransactionManager.rollback(transaction);
}
});
}
}
然后问题来了:如何保证所有子线程的数据是同一“事务”下
目前能想到的是两种:
- 各个线程之间通过发布,轮询或者监听的方式获得对方的处理状态;比如A线程于B线程,A线程监听B线程是否在commit节点,B线程同样判断A线程是否在commit节点;
- 将主线程事务共享到子线程中;
首先是第一种,节点式判断:
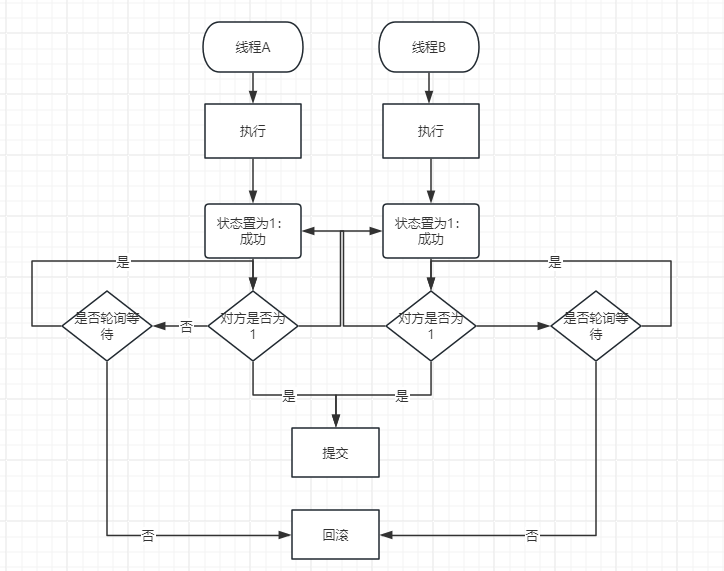
上图可见,我们需要侧重的是两点:
- 线程共享可见的状态,表示处理成功或失败
- 轮询等待重试以及超时机制
我们用表格表示状态:
| 时间序号 | 线程A | 线程B |
|---|---|---|
| 1 | 开始 | 开始 |
| 2 | 执行,处理数据 | 执行,处理数据 |
| 3 | 完成,状态设置为1 | 执行,处理数据 |
| 4 | 询问线程B状态 status ==1 | 执行,处理数据 |
| 5 | 否,等待,时间计数+1 | 执行,处理数据 |
| 6 | 否,等待,时间计数+1 | 执行,处理数据 |
| 7 | 否,等待,时间计数+1 | 执行,处理数据 |
| 8 | 三次超时,状态设置为2 | 完成,状态设置为1 |
| 9 | 回滚 | 询问线程A状态,线程A status==2,回滚 |
| 10 | 结束 | 结束 |
在节点为4时,设计一个其他线程可见的变量供对方轮询;
简单的可以直接使用volatile 修饰出对方可访问到的变量;
也可以使用CyclicBarrier或CountDownLatch 通过阻塞的办法做到通知对方是否执行提交的方式
public void mainThread() {
CountDownLatch countDownLatch = new CountDownLatch(10);
for (int i = 0; i <= 9; i++) {
CompletableFuture.runAsync(() -> {
TransactionStatus transaction = platformTransactionManager.getTransaction(new DefaultTransactionDefinition());
try {
excelDao.save(null);
countDownLatch.countDown();
countDownLatch.await(30,TimeUnit.SECONDS);
platformTransactionManager.commit(transaction);
}catch (Exception e){
platformTransactionManager.rollback(transaction);
}
});
}
}
不过这样就衍生出了另外的问题:
当线程收到放开阻塞命令后,开始提交,但是线程A在提交事务的过程中线程中断导致回滚,线程B依然提交事务;
那么我们是否还需要额外开启一个任务去监听各个线程的事务提交情况,并且为其准备对应的补偿回滚机制;
public void mainThread() throws InterruptedException {
CountDownLatch countDownLatch = new CountDownLatch(10);
AtomicInteger atomicInteger = new AtomicInteger(0);
for (int i = 0; i <= 9; i++) {
CompletableFuture.runAsync(() -> {
TransactionStatus transaction = platformTransactionManager.getTransaction(new DefaultTransactionDefinition());
try {
excelDao.save(null);
countDownLatch.countDown();
countDownLatch.await(30, TimeUnit.SECONDS);
platformTransactionManager.commit(transaction);
atomicInteger.incrementAndGet();
} catch (Exception e) {
platformTransactionManager.rollback(transaction);
}
});
}
countDownLatch.await();
//三阶段确认
if (atomicInteger.get() == 10) {
//操作成功
}else{
//补偿
}
}
看到这,就跟另一个东西非常像了:分布式事务-TCC。所以多线程事务处理 基本约等于 分布式事务;
差别是前者是基于单机实现的,所以纯内存操作在性能上可以允许很简便的方式,也可以引入中间件往大的设计进行优化,比如说上述的代码,我们可以优化为:
- 发送mq消息队列
- 在消费者端进行数据处理,并且将自己的状态-线程信息保存在redis缓存中
- 同样等待,不过差别在于使用消息队列可以将等待逻辑交给mq实现,在消费端发布一条新的处理消息到队列中;
- 所以线程准备就绪,开始事务提交
- ....
通过mq+redis的方式实现了单机内存的一个缺陷:程序崩溃时的部分提交无法恢复问题
但是第一种子线程各自管理事务的方式有一个非常非常大的缺陷和问题: 子线程会占据事务阻塞,并且多线程操作同时提交事务时,可能会同时占据大量的数据库连接;
所以我们有没有办法在只有一次事务提交管控的背景下,针对多线程实现事务呢;
第二种
ThreadLocal 我们都知道可以实现当前线程中的数据共享;
但是在当前线程中,子线程是无法访问到父线程的ThreadLocal的:

好在,Jdk实现了InheritableThreadLocal,使子线程与父线程的访问空间是一个Map,具体原理不提在本篇中;
基于这个我们可以将事务连接放在InheritableThreadLocal中,实现第一种结尾所提的将子线程事务提交放在主线程中;
同时还可以使用本地消息表控制事务还原和线程执行状态;
不过这样也会出现一个我们不想面对的问题:长事务
所以使用哪种,一定要根据服务器性能和需求考量,偏向第一种;
顺序管理
保证顺序的前提是保证多线程事务;
在事务得到保证的前提下,顺序问题就变得很好处理了;
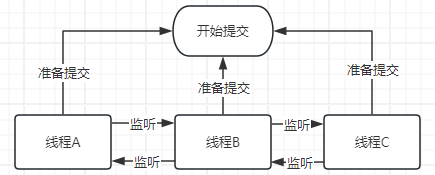
事务提交的前置任务:双向监听上一个节点与下一个节点的状态,对应事务提交和判断是否需要回滚
所以保证顺序,不可避免的需要在保证事务的同时额外进行上一个节点的监听和等待;
问题:
- 事务被拉的很长
- 性能消耗很大,线程B在监听线程A是否提交事务,完成本身的事务提交任务后,还要监听下一个节点的事务提交状态,如果下一个节点出现错误,要往上一个一个节点的上报回滚命令
- ...
总结
冲突点是:单机环境下,多线程还要保证事务;
让人不得不汗颜,都多线程了还保证个屁的事务;
所以推荐大伙自己去魔改一个Connection和ThreadLocal;
或者爆改单机应用,将这个需求分散到各个子级服务下,引入seata,这样就变成了分布式事务问题