Xxl-Job源码架构阅读和分析
Xxl-Job源码架构阅读和分析
xxl-job是一个业内非常认可的任务调度平台,整体架构清晰,流程也不复杂(不像Dubbo或者Skywalking...那样绕来绕去)
所以如果想自己搭建一个任务调度平台,读xxl-job的源码一定是一个可快速了解任务调度系统设计相关的捷径;
架构
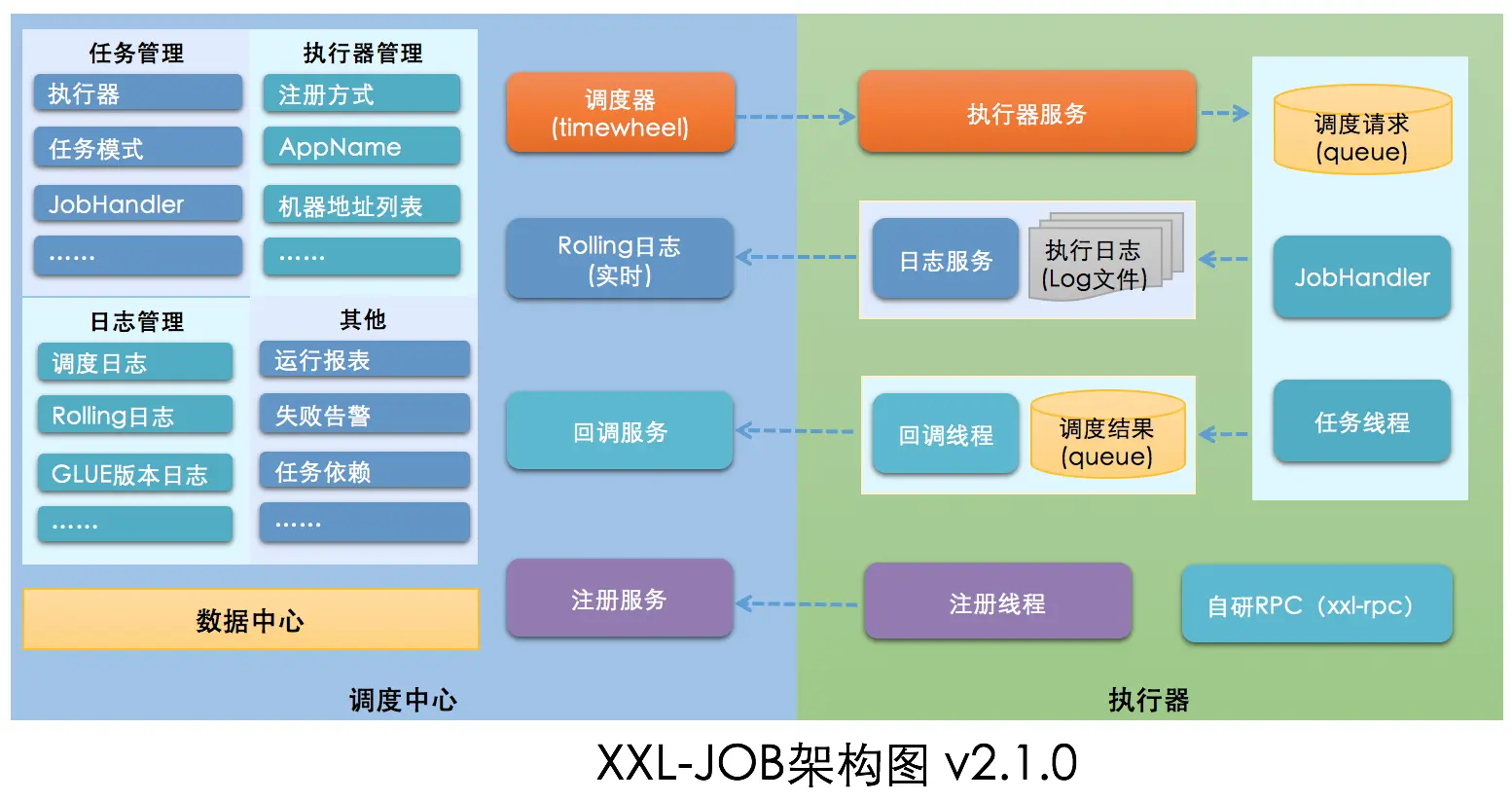
来自https://www.xuxueli.com/xxl-job/的架构图;
分为调度中心的服务端和执行器服务的客户端
客户端仅做执行任务以及与服务端的基本通讯,包括注册、回调...
服务端则是基于任务调度这一业务的各类衍生功能:日志、预警、统筹等等...
整体
作为一个从15年就开始搭建的系统,整体架构经过了无Spring -> Spring -> SpringBoot 拆箱即用的历程
代码中有一股很原始的野味,很多地方没有Spring的环环绕绕,直来直去也使得整体的架构阅读起来非常非常的清晰明确;
整体来看,完整的调度中心一定是由至少一个客户端(被调度者)和一个服务端(调度者)组成;各有其职,互不干扰,以Http进行通讯;
客户端负责:
- 注册执行器
- 执行定时任务
- ...
服务端负责:
- 收集执行器
- 触发定时任务
- ...
客户端存活判断以及各类日志记录、回调、注销 ...等等操作则是双方约定俗成的细节层面。
在xxl-job中两端的通讯指令分别有:
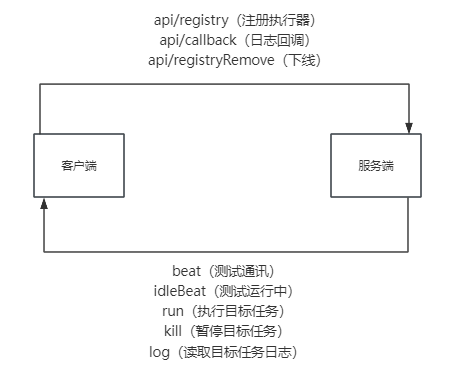
所以从整体上来看,只需要了解各方的指令发起与结束的链路就可以弄清整个xxl-job 的运行流程
客户端
客户端是引入 xxl-job-core 包后拆箱即用即装载
<dependency>
<groupId>com.xuxueli</groupId>
<artifactId>xxl-job-core</artifactId>
</dependency>
现版本的xxl-job与SpringBoot环境强绑定,见XxlJobSpringExecutor 类客户端项目启动的初始化方法:

初始化动作有三步:
- 组装被
@xxlJob注解修饰的类和方法,注册任务执行器 - 初始化默认参数,日志、令牌、路由....
- 启动客户端netty通讯,与服务端通讯
1\ 注册任务执行器
private void initJobHandlerMethodRepository(ApplicationContext applicationContext) {
if (applicationContext == null) {
return;
}
String[] beanDefinitionNames = applicationContext.getBeanNamesForType(Object.class, false, true);
for (String beanDefinitionName : beanDefinitionNames) {
// get bean
Object bean = null;
Lazy onBean = applicationContext.findAnnotationOnBean(beanDefinitionName, Lazy.class);
if (onBean!=null){
logger.debug("xxl-job annotation scan, skip @Lazy Bean:{}", beanDefinitionName);
continue;
}else {
bean = applicationContext.getBean(beanDefinitionName);
}
Map<Method, XxlJob> annotatedMethods = null;
try {
annotatedMethods = MethodIntrospector.selectMethods(bean.getClass(),
new MethodIntrospector.MetadataLookup<XxlJob>() {
@Override
public XxlJob inspect(Method method) {
return AnnotatedElementUtils.findMergedAnnotation(method, XxlJob.class);
}
});
} catch (Throwable ex) {
logger.error("xxl-job method-jobhandler resolve error for bean[" + beanDefinitionName + "].", ex);
}
if (annotatedMethods==null || annotatedMethods.isEmpty()) {
continue;
}
for (Map.Entry<Method, XxlJob> methodXxlJobEntry : annotatedMethods.entrySet()) {
Method executeMethod = methodXxlJobEntry.getKey();
XxlJob xxlJob = methodXxlJobEntry.getValue();
// regist
registJobHandler(xxlJob, bean, executeMethod);
}
}
}
这里是使用MethodIntrospector 的selectMethods方法,搭配Spring的ApplicationContext bean对象前后文获取所有被@xxlJob注释修饰的method;
其中过去由于未处理 @Lazy 注解,导致本该懒加载的类在此处获取所有类时被强行加载导致懒加载失效;(现已修复)
最终在 registJobHandler 方法中,也是非常简单的将xxlJob.value 作为key,通过前文获取的Class、Method、xxlJob.init、xxlJob-destory 组装的MethodHandler 作为Value,塞到ConcurrentMap中
2\ 初始化基本参数
public void start() throws Exception {
// init logpath
XxlJobFileAppender.initLogPath(logPath);
// init invoker, admin-client
initAdminBizList(adminAddresses, accessToken);
// init JobLogFileCleanThread
JobLogFileCleanThread.getInstance().start(logRetentionDays);
// init TriggerCallbackThread
TriggerCallbackThread.getInstance().start();
// init executor-server
initEmbedServer(address, ip, port, appname, accessToken);
}
很简单的基本信息与配置的初始化设置:
- 日志地址设置
- 服务端列表的记录
- 日志清理线程的开启
- 日志回调线程的开启
- netty通讯客户端参数的设置
这里需要注意的是,在xxlJob中针对线程的一个处理:历史遗留问题
上文有提到xxlJob是从16年开始开源,但是具体开发时间可能更早,也就导致了当时的系统定时任务的设计有一些瑕疵,比方说日志清理线程:
localThread = new Thread(new Runnable() {
@Override
public void run() {
while (!toStop) {
try {
File[] childDirs = new File(XxlJobFileAppender.getLogPath()).listFiles();
if (childDirs!=null && childDirs.length>0) {
//................
for (File childFile: childDirs) {
//................
if ((todayDate.getTime()-logFileCreateDate.getTime()) >= logRetentionDays * (24 * 60 * 60 * 1000) ) {
FileUtil.deleteRecursively(childFile);
}
}
}
} catch (Exception e) {
//................
}
try {
TimeUnit.DAYS.sleep(1);
} catch (InterruptedException e) {
if (!toStop) {
logger.error(e.getMessage(), e);
}
}
}
}
});
可以看到开启一个死循环线程,使用外置的boolean参数控制,执行一次之后线程 Sleep 1天
这种类型的操作,其实在一个定时任务调度中心系统来看,完全可以由服务端初始化自动生成一个基于客户端的每天执行一次的日志清理任务,资源消耗到服务端而非客户端。
3\ 开启服务端通讯
通讯分为两部分:
- 向服务端发送的心跳注册包(存活)
- 与服务端的指令交换,比如回调、命令执行...
注册包:
在 ExecutorRegistryThread 中,使用了前文提到的死循环线程:
public void run() {
while (!toStop) {
try {
//................
for (AdminBiz adminBiz: XxlJobExecutor.getAdminBizList()) {
try {
ReturnT<String> registryResult = adminBiz.registry(registryParam);
if (registryResult!=null && ReturnT.SUCCESS_CODE == registryResult.getCode()) {
registryResult = ReturnT.SUCCESS;
break;
}
} catch (Exception e) { }
}
} catch (Exception e) {
//................
}
try {
if (!toStop) {
TimeUnit.SECONDS.sleep(RegistryConfig.BEAT_TIMEOUT);
}
} catch (InterruptedException e) {
//................
}
}
try {
//................
for (AdminBiz adminBiz: XxlJobExecutor.getAdminBizList()) {
try {
ReturnT<String> registryResult = adminBiz.registryRemove(registryParam);
if (registryResult!=null && ReturnT.SUCCESS_CODE == registryResult.getCode()) {
registryResult = ReturnT.SUCCESS;
break;
}
} catch (Exception e) {
//................
}
}
} catch (Exception e) {
//................
}
}
每一次执行完,睡眠30s,因此注册包是固定的每30s上报一次;
当项目暂停时,则向服务端发送注销指令;
指令包
客户端使用以下线程池接收服务端指令:
ThreadPoolExecutor bizThreadPool = new ThreadPoolExecutor(
0,
200,
60L,
TimeUnit.SECONDS,
new LinkedBlockingQueue<Runnable>(2000),
new ThreadFactory() {
@Override
public Thread newThread(Runnable r) {
return new Thread(r, "xxl-job, EmbedServer bizThreadPool-" + r.hashCode());
}
},
new RejectedExecutionHandler() {
@Override
public void rejectedExecution(Runnable r, ThreadPoolExecutor executor) {
throw new RuntimeException("xxl-job, EmbedServer bizThreadPool is EXHAUSTED!");
}
});
线程池无法配置,写死固定;因此在xxlJob中客户端最大能支持的并发任务量 = 空闲核心*2000,拒绝策略为抛出异常
在EmbedHttpServerHandler中netty接收消息,处理以下指令集:
- /beat 纯测试
- /idleBeat 测试有无在运行的队列
- /run 执行目标任务
- /kill 暂停目标任务
- /log 读取目标任务
在调度中心中,我们只需要关注客户端如何执行目标动作 /run指令;
在这个指令中,客户端的处理仅仅只是将服务端发送给来的以下参数:
{
"jobId":1,
"glueType": "BEAN" ,// 任务模式
"executorHandler":"xxlJobalue", //@xxljob中的value
"executorParams":"执行时的上下文参数"
//...
}
解析拿到初始化时注册的任务执行器,封装成一个线程并且开启,放到本地内存中,key为jobId


线程开启后,再将本次需要执行的任务参数,也就是服务端发送过来的信息推到此线程的待执行队列中;
并且,当待执行队列中有本次任务的JobId时,报错提示任务执行中;
而这个线程的动作也就很简单了,又是一个死循环从待执行队列中拿到任务,执行;
//本地请求的上下文 InheritableThreadLocal
XxlJobContext xxlJobContext = new XxlJobContext(
triggerParam.getJobId(),
triggerParam.getExecutorParams(),
logFileName,
triggerParam.getBroadcastIndex(),
triggerParam.getBroadcastTotal());
XxlJobContext.setXxlJobContext(xxlJobContext);
if (triggerParam.getExecutorTimeout() > 0) {
//设置了超时时间时执行
Thread futureThread = null;
try {
FutureTask<Boolean> futureTask = new FutureTask<Boolean>(new Callable<Boolean>() {
@Override
public Boolean call() throws Exception {
XxlJobContext.setXxlJobContext(xxlJobContext);
handler.execute();
return true;
}
});
futureThread = new Thread(futureTask);
futureThread.start();
Boolean tempResult = futureTask.get(triggerParam.getExecutorTimeout(), TimeUnit.SECONDS);
} catch (TimeoutException e) {
XxlJobHelper.log("<br>----------- xxl-job job execute timeout");
XxlJobHelper.log(e);
XxlJobHelper.handleTimeout("job execute timeout ");
} finally {
futureThread.interrupt();
}
} else {
// 执行
handler.execute();
}
这块代码阅读提了个Issues :https://github.com/xuxueli/xxl-job/issues/3546

在任务执行完成之后,该任务的线程缓存会保留30s,30s内没有任务过来清除该线程内存:
if (idleTimes > 30) {
if(triggerQueue.size() == 0) {
XxlJobExecutor.removeJobThread(jobId, "excutor idel times over limit.");
}
除此之外,任务执行开始时,执行中,执行后;
分别都会向日志回调线程中的待执行队列里推入当前日志,日志回调线程的处理和上文中提到的所有线程一模一样(历史遗留问题)。
这也是xxlJob源码非常容易阅读的原因
服务端
服务端由于有页面的操作,所以接口和服务比较多:新增、更新、删除、导出、图表、注册等等....大多是简单的CRUD;
所以本文只关注 xxlJob 如何完成任务调度这一核心功能;
一个任务的发起一定有以下三步:
- 找到需要执行的任务
- 执行任务
- 整理残局
1\ 执行任务发现
xxlJob 也不例外,也是先找到需要执行的任务,在JobScheduleHelper类中:
开启一个每1s执行一次的循环线程任务:
public static final long PRE_READ_MS = 5000;
public void run() {
TimeUnit.MILLISECONDS.sleep(5000 - System.currentTimeMillis()%1000 );
//一次执行的最大任务量
int preReadCount = (XxlJobAdminConfig.getAdminConfig().getTriggerPoolFastMax() + XxlJobAdminConfig.getAdminConfig().getTriggerPoolSlowMax()) * 20;
while (!scheduleThreadToStop) {
//.................
try {
//基于数据库 拿到一把全局锁
preparedStatement = conn.prepareStatement( "select * from xxl_job_lock where lock_name = 'schedule_lock' for update" );
preparedStatement.execute();
long nowTime = System.currentTimeMillis();
//查询执行时间在未来5秒内的任务
List<XxlJobInfo> scheduleList = XxlJobAdminConfig.getAdminConfig().getXxlJobInfoDao().scheduleJobQuery(nowTime + PRE_READ_MS, preReadCount);
//.................
循环出本次时间片中需要执行的任务,往下走进入判断与分支处理流程,三种情况:
- 查询5秒内任务或者其他因素导致,当前时间超过了查询sql时未来10s的时间
- 查询5秒内任务或者其他因素导致,当前时间超过了查询sql时未来5s的时间
- 正常情况,5s内的任务
前两者根据任务类型,直接执行任务做补偿动作;
第三个则是将所有任务,根据 (执行时间/1000)%60 得到的均衡偏移量的方式推到一个一秒执行一次线程的队列中:
int ringSecond = (int)((jobInfo.getTriggerNextTime()/1000)%60);
//............
// push async ring
List<Integer> ringItemData = ringData.get(ringSecond);
if (ringItemData == null) {
ringItemData = new ArrayList<Integer>();
ringData.put(ringSecond, ringItemData);
}
ringItemData.add(jobId);
而这个一秒一次(存在偏移)的线程所做的事就显然易见了:

因此一个任务的执行时间会被分片在5S内的一个随机的权重上,然后每秒中存在两次执行的可能。最坏的情况任务会存在5s的提前执行或者4s的延时执行。
2\ 任务调度
在 JobTriggerPoolHelper 中,开启了两个线程:
fastTriggerPool = new ThreadPoolExecutor(
10,
XxlJobAdminConfig.getAdminConfig().getTriggerPoolFastMax(),
60L,
TimeUnit.SECONDS,
new LinkedBlockingQueue<Runnable>(1000),
new ThreadFactory() {
@Override
public Thread newThread(Runnable r) {
return new Thread(r, "xxl-job, admin JobTriggerPoolHelper-fastTriggerPool-" + r.hashCode());
}
});
slowTriggerPool = new ThreadPoolExecutor(
10,
XxlJobAdminConfig.getAdminConfig().getTriggerPoolSlowMax(),
60L,
TimeUnit.SECONDS,
new LinkedBlockingQueue<Runnable>(2000),
new ThreadFactory() {
@Override
public Thread newThread(Runnable r) {
return new Thread(r, "xxl-job, admin JobTriggerPoolHelper-slowTriggerPool-" + r.hashCode());
}
});
参数名可见,一个快任务触发器,一个慢任务触发器
快慢依照的标准并非任务本身,而是快线程中的任务执行中的超时线程(大于500ms执行时间的)的总数:
ThreadPoolExecutor triggerPool_ = fastTriggerPool;
AtomicInteger jobTimeoutCount = jobTimeoutCountMap.get(jobId);
if (jobTimeoutCount!=null && jobTimeoutCount.get() > 10) {
triggerPool_ = slowTriggerPool;
}
这样的小小设计给了任务调度很大的弹性空间,至少避免了慢任务的堆积;虽然只有两个执行空间,但是仔细考虑多了浪费资源,两个也刚刚好;
具体的任务执行很简单,将在页面上设置好的参数封装好发给客户端的 netty 客户端,指令为 /run
如此一来就完成了任务调度的动作
3\ 残局处理
任务调度发起成功后,首先是记录本次调度日志;
然后是更新执行时间,将本次执行任务的 triggerNextTime +5s更新到数据库中;这里需要说明一点,由于寻找未来5s的轮询操作,一个任务设置每秒执行一次时的最坏的偏差可能可达5s
然后是判断本次 1 \执行任务发现 动作的睡眠时间:
long cost = System.currentTimeMillis()-start;
// Wait seconds, align second
if (cost < 1000) { // scan-overtime, not wait
try {
// pre-read period: success > scan each second; fail > skip this period;
TimeUnit.MILLISECONDS.sleep((preReadSuc?1000:PRE_READ_MS) - System.currentTimeMillis()%1000);
} catch (InterruptedException e) {
if (!scheduleThreadToStop) {
logger.error(e.getMessage(), e);
}
}
}
最高是每秒进行一次发现;
任务执行之后,服务端等待客户端目标任务调用回调指令更新日志,直接任务结束。
总结
可见xxljob是一个设计很简单明了但是非常好用的系统,虽然在查阅过程中发现有大量的代码块,设计存在更好的模式,更好的性能和扩展性替代。
但是从16年到现在的开源系统能被这么多的公司选型,也证明了系统各个线程设计的合理性;
查阅之后,未来搭建自己体系的任务调度中心思路也就非常明确;😀