算法,他真的不简单

虽然我们90%的工程师都在用你写的Homebrew,但这也并没有什么卵用,你连二叉树翻转都写不出,直接滚蛋吧!
Max Howell【Homebrew作者】在2015年面试谷歌的故事很多人都知道,这本是一个面试官放水,求职者水过的喜剧片,却被主角演成了逗比,在当时也带来了一系列的讨论,算法有什么用?这么牛的人连翻转二叉树都写不出,我上我也行...
所以今天给大伙带来一些我上我也行的算法

猴子与睡眠排序
数学家爱丁顿曾提出过一个有趣的理论,他说:
如果有足够多的猴子利用足够多的打字机,每时每刻都在打字,那么早晚有一天会打出大英博物馆所有的书(也有说是能打出一部莎士比亚的著作)
在2004年,模拟中有一只猴子打出了一段字符:“VALENTINE. Cease toIdor:eFLP0FRjWK78aXzVOwm)-‘;8.t”。后面这段比较怪异,因为这就是虚拟的猴子胡乱打出来的,不过这段字符的前面一小部分,的确和莎士比亚戏剧《维洛那二绅士》中的一段是相同的。
不过经过计算,该虚拟猴子出现的时间,远超我们想象:4216250000000亿亿年!
其实这个理论的根本内容很简单,那就是不论一件事的概率有多么小,当这个概率乘以一个无限大的基数时,就一定会发生。这个理论就这么简单,只不过爱丁顿把它给戏剧化了一下而已。
那么对于排序算法来说,是否也可以有一只猴子完成排序?

猴子排序
现在我有这么一个数组
Integer [] arr = new Integer []{6,4,1,7,8,9};
那么作为一只猴子是不知道什么是排序的,所以他把这个数组打乱
List<Integer> arrrs= Arrays.asList(arr);
//打乱集合元素
Collections.shuffle(arrrs);
然后我们判断,猴子打乱后的数组是否是有序数组,如果有序,那么这只猴子就是那只写出 "莎士比亚"的猴子
for(int i=0;i<arrrs.size()-1;i++){
if(arrrs.get(i + 1) < arrrs.get(i)){
break;
}
}
如果这只猴子不是我们要找的那只,那么我们准备下一只猴子;;如此无限,直到找到正确的那只,我们的排序就完成了
public static void monkeySort(){
Integer [] arr = new Integer []{6,4,1,7,8,9};
List<Integer> result = null;
int d = 0;
back: while(true){
System.out.println(d+++"次");
List<Integer> arrrs= Arrays.asList(arr);
//打乱集合元素
Collections.shuffle(arrrs);
for(int i=0;i<arrrs.size()-1;i++){
if(arrrs.get(i + 1) < arrrs.get(i)){
continue back;
}
}
result = arrrs;
break;
}
for(Integer i :result){
System.out.println(i);
}
}
作为一个算法,抛开时间\空间复杂度不谈,哲学系的感觉我认为是TOP one的。
什么,你需要一个最高级别排序的算法?OK,我带来一个O(N)级别,多线程,并发排序的算法

睡眠排序
还是那个数组
Integer [] arr = new Integer []{6,4,1,7,8,9};
那么都说了是最高级别了,那么我们就要带入CPU:线程
我们为数组中的每一个元素单独开一个线程用作排序
for (int i = 0; i < arr.length; i++) {
new Thread(() ->{
}).start();
}
那么线程中我们做什么,可以让每个元素,在他排序的位置上出现?
睡眠,Thread.sleep,只要将他们睡到应该醒的时间,起来的那一刻,他就是有序的位置。
如果有负数? 那就把所有睡眠时间转成 UInt32 !
for (int i = 0; i < arr.length; i++) {
long time = arr[i];
final int j = i;
new Thread(() ->{
try {
Thread.sleep(time);
} catch (InterruptedException e) {
e.printStackTrace();
}
}).start();
}
然后我们上点并发的技术用来收集
public static void sleepSort() {
Integer[] arr = new Integer[]{1, 5, 3, 2, 8,4,100,400,200};
Arrays.sort(arr);
CopyOnWriteArrayList<Integer> cwa = new CopyOnWriteArrayList<>();
for (int i = 0; i < arr.length; i++) {
long time = arr[i];
final int j = i;
new Thread(() ->{
try {
Thread.sleep(time);
} catch (InterruptedException e) {
e.printStackTrace();
}
cwa.add(arr[j]);
}).start();
}
//等待数组排序完成
while(cwa.size()!=arr.length){
}
for(Integer num:cwa){
System.out.println(num);
}
}
免责声明:以上排序,切勿出现在生产中

有效算法
说到排序,不得不提提尝用到的:
int[] arr = new int[]{1, 5, 3, 2, 8,4,100,400,200};
Arrays.sort(arr);
Arrays.sort()方法
JAVA-Arrays.sort
关于这个Java中的常驻方法,在 Java8-Arrays.sort 中有详细的介绍,感兴趣的可跳转,这里就不重复赘述了
总之:Java采取分类讨论+最大功率使用CPU功效,双轴快排方式排序
二分查找
有用过盗版视频网站或盗版小说网站都有过这样的体验,前面XX话好好的,突然从某一话开始,后面的资源内容都消失不见了。
如果你有写过爬虫,去"下载"电视剧或小说资源,就会明白其中的一些原因:
首先盗版网站的资源不一定是从正版软件上拉下来的,更多是去盗竞品网站的资源,这也导致了,资源001,002,003都是好好的,但是从004开始,竞品网站的上传任务失败,造成了我拉到004开始后的所有资源,005,006,007都是失败的。
那么以上案例,能给你带来一个什么算法灵感呢?
完善背景:
爬虫已经将某网站的某电视剧资源的下载URL整合,并且发现URL都是 XXXX电视剧名_01,02,03【集数】 样式的路径,将其集数URL顺序排序,接下去我们需要下载这些URL到我们磁盘中
下载流程:
开多个 下载线程 ,然后去同一个List中取URL,当下载成功时,则从List中remove,如果有线程资源报错,则终止线程,通知所有线程停止工作,等待未下载线程处理完毕。
问题:
- 由于我们不知道资源的有用率,所以无法控制下载线程的数量,尽可能大,这也导致了我们对网站的访问量的增大,违反了爬虫条例。
- 由于网络问题,下载时可能会抛异常,但非资源错误,这时候需要重试、再爬取等额外处理,导致不并要的资源消耗
- 线程并发、下载资源重复问题
- ...
我们从算法的角度去设计一个比较好的思路:
我们已知资源的总数,那么只需要知道从哪个URL开始,后续的资源是已损坏的。就可以去规划需要开启多少个下载线程及总有效资源块了。
将URL抽象成 1和0,0是无效资源,1是有效资源
因为URL是通过集数排序,所以 看到的很可能是 1,1,1,1,1,0,0,0,0,0
这样的数组
所以我们只需要找到最右边的那个1的位置,就可以知道总有效资源下载数了。
即可以使用二分查找的方式,最快的找到最右边的那个1
Trie 树 字典
有这样一个简单的场景:

级联树,但因为后台同志设计时基于数据对象考虑的问题,前端拿到的是一组:
ar data = [{
"nav": "指南",
"menu": "设计原则",
"content": "一致"
}, {
"nav": "指南",
"menu": "设计原则",
"content": "反馈"
}, {
"nav": "指南",
"menu": "导航",
"content": "侧向导航"
}, {
"nav": "组件",
"menu": "Basic",
"content": "Layout 布局"
.......
......
}]
这样的数组对象。
如果keys和对象层级少还好,可以通过逐一遍历的方式,组装成一颗树。
但一定keys值不保证,以及级联层级高,都会导致渲染慢,代码复杂,容易出错等问题
那么以上背景,能给你带来一个什么算法灵感呢?
字典树
引入字典树进行业务设计,首先简单的介绍一下字典树是一个什么东西
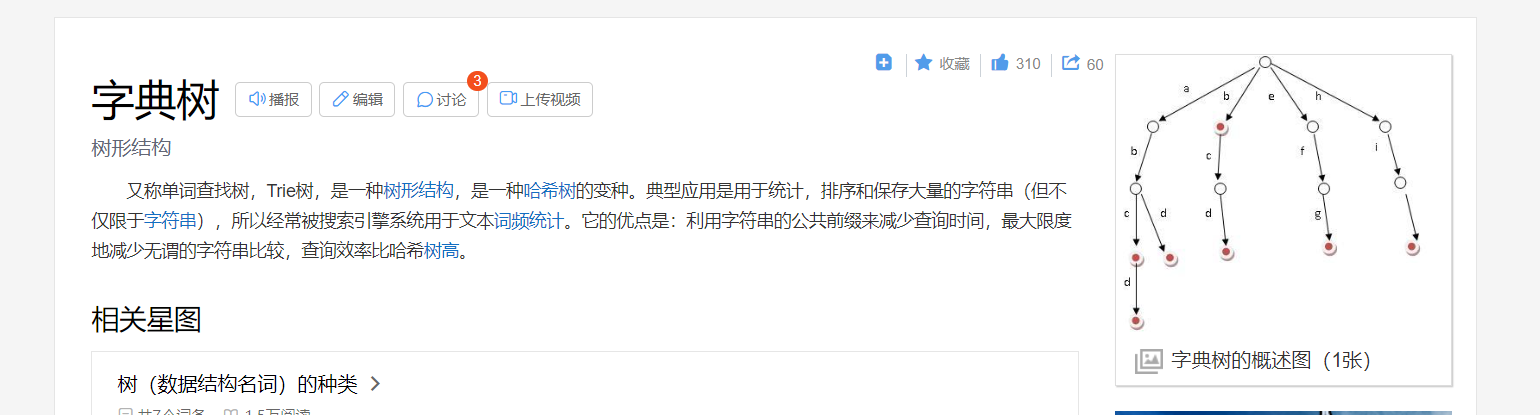
它是一颗,根节点没有元素,然后任一节点的组成单词即是根节点到目标节点的组合单词,是一颗用于单词搜索的变种树。
不过在这里,字典树的基本属性及构造就不展开赘述,看代码:
var transObject = function(tableData, keys) {
let hashTable = {}, res = []
for (let i = 0; i < tableData.length; i++) {
let arr = res, cur = hashTable
for (let j = 0; j < keys.length; j++) {
let key = keys[j], filed = tableData[i][key]
if (!cur[filed]) {
let pusher = {
value: filed
}, tmp
if (j !== (keys.length - 1)) {
tmp = []
pusher.children = tmp
}
cur[filed] = { $$pos: arr.push(pusher) - 1 }
cur = cur[filed]
arr = tmp
} else {
cur = cur[filed]
arr = arr[cur.$$pos].children
}
}
}
return res
}
var data = [{
"nav": "指南",
"menu": "设计原则",
"content": "一致"
}, {
"nav": "指南",
"menu": "设计原则",
"content": "反馈"
}, {
"nav": "指南",
"menu": "导航",
"content": "侧向导航"
}, {
"nav": "组件",
"menu": "Basic",
"content": "Layout 布局"
}]
var keys = ['nav', 'menu', 'content']
console.log(transObject(data, keys))
这是一段 来自 https://github.com/LeuisKen/leuisken.github.io/issues/2 对于级联树的优化代码
简单的解析:
- 取第一个对象的第一个key,判断当前根节点上有没有挂着指南的元素,如果有,则切换到该节点上;如果没有,则新建一个名为 指南 字符的节点,作为根节点的叶子节点,并且切换到该节点上。
- 取第一个对象的第二个key,判断当前当前下有无 设计原则 节点,如果有,则切换到该节点上;如果没有,则新建一个名为 设计原则 字符的结点,作为根节点的叶子节点,并且切换到该节点上。
- .....
- 取第二个对象的第一个key,发现已经有 指令 元素节点,切换到该节点
- ...
- 取第二个对象的第三个key,.....
如此重复以上判断,知道元素遍历完成。
这样我们就会得到一个这样的对象:

是不是和字典树的构造一样
搜索Dfs和Bfs
首先搜索算法的思路是一个用度比较广的设计
比如树的迭代,循环解析,统合对象等等都有用到的场景
背景: 一个场景的执行指令,包括执行动作和执行另一个场景; 需要拿到一个场景的所有执行指令。
这里其实就是套娃的对象,需要解析出所有基本属性。
我们可以使用迭代,使用For循环,但是如果采用了Dfs的一些思路,代码会显得非常优雅。
private List<指令> depthSearch(List<场景对象> scenes) {
if (CollectionUtil.isEmpty(scenes)) return CollectionUtil.newArrayList();
//深度查找
List<指令集合> result = new ArrayList<>();
//唯一指令
Set<String> unitCommand = new HashSet<>();
//防止套娃
Set<Integer> filterScenesId = new HashSet<>();
Stack<场景对象> statck = new Stack<>();
statck.addAll(scenes);
while (!statck.empty()) {
场景对象 pop = statck.pop();
if (filterScenesId.contains(pop.getScenesId())) continue;
//如果指令是执行另一个场景
if (ObjectUtil.isNull(pop.getExecScenesId())) {
//设备指令
String unitC = pop.get(指令唯一编码);
if (!unitCommand.contains(unitC)) {
result.add(pop);
unitCommand.add(unitC);
}
} else {
//场景指令
Integer execScenesId = pop.getExecScenesId();
List<场景对象> scenesCommandDOS = dao.查询该场景的所有执行指令
if (CollectionUtil.isNotEmpty(scenesCommandDOS)) {
statck.addAll(ScenesCommandConvert.INSTANCE.dos2Dto(scenesCommandDOS));
}
}
//套娃场景 只处理一次
filterScenesId.add(pop.getScenesId());
}
return result;
}
整个处理都会比较线性,可读性很高。
总结
简单的介绍一下,一些简单的算法对我们一些场景业务场景的设计影响。
除了以上以外,像LRU、背包算法、滑动窗口等等等等,在众多框架、工具中都有体现。
但是,其实我们都知道,算法这东西在开发中其实基本都没什么用,而且我们也不需要去学习什么,脑筋急转弯式的数据结构及算法。
但是LRU是什么,双向链表是什么,树有什么作用等等等等,如果使用在特定的业务中,一定是一种新鲜的体现。比如对最远使用者的淘汰、深度优化查找的两种方式等