条件决定任务执行需求设计「自动化场景」
自动化场景
自动化场景,白话点来说,即「由一个或多个条件决定任务是否执行」的功能。
对于这种模式的功能,任务方面的开发并不难,整个功能的难度是随着条件的多种化而变动的。
本文将提出以下几点,当他们作为条件时的需求开发难题及对应的解决方式。
定时
首先定时应该是这类模式功能最常见的条件;
比如我们经常接触的「闹钟」
当时间到达某个时间点时,任务触发。
那么关于时间点是否到达的判断也有两种不同的说法:
- 秒级判断
- 分级判断
由需求决定解决方案,当功能要求秒级定时,就像闹钟一样;当功能要求分级时,由于时间限度被拉长,业务可执行时间也会变长。
不过由于个体应用级别不同,下面将分享一下我对于负载健康时以及资源贫乏时的解决方案。
负载健康
在应用无需担心性能问题时:
1、最暴力的肯定是逐秒去判断当前时间是否有可执行的条件,而怎么去获取,不管是通过DB还是缓存差距都不会大。
2、将一天分为若干个时间片,比如24片;在进入当前时间片的那一刻,将符号当前时间片时间的条件全部拿出来,放入当前时间片中待处理数据队列中,等待处理器逐秒判断。
简单原理如下图:

优点:相比暴力逐秒判断,有两个明显的优势,一是获取当前时间数据的动作变少,同时也会更好管理;二是逐秒判断变成了一个可能执行的行为。
3、采用两个线程构建一个时间循环,和玩一个圈内的接力游戏一样:
第一个线程执行完之后,获取第二个线程的待判断时间数据;
第二个线程拿到数据,开始执行,执行完了之后做线程一,一样的动作;
简单原理图如下:
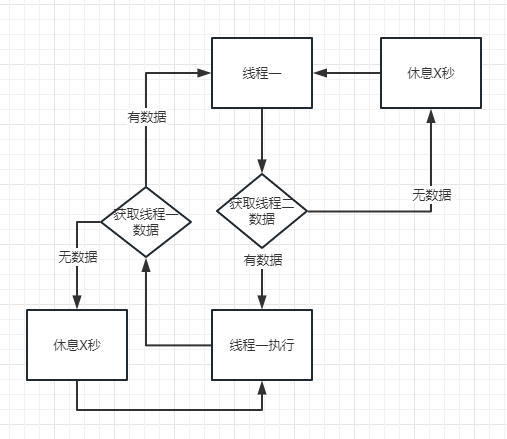
优点:线程创建少的同时,逐秒判断也变成了一个可能执行的行为。同时也可以跨时间去删减待判断时间数据
缺点:待判断数据的一致性问题
资源贫乏
当当前应用无法支持逐秒判断的线程时,就必须引入第三方服务或是插件了;
这里推荐使用RabbitMq的延时队列,延时插件:https://github.com/rabbitmq/rabbitmq-delayed-message-exchange/releases
不过这是在消息队列压力不大的前提下采取的最有利方案,同替平也有很多。
除此之外,也可以考虑采用缓存过期、DelayQueue等方式最低限度的降低逐秒判断的动作
当然了,最佳方案是直接加个服务器.😃
天气
天气作为条件,面临的最大问题是随着天气条件数量的增多,由于每个条件需要的经纬度不同;
导致当前的天气数据也会随着条件数量的增多,逐渐变大。
同时,由于天气具有时效性,在小时制、半天制、一天制甚至分/半小时制中对天气数据的爬取要求又会逐步变高。
最后我们需要面对的是两个问题:
- 存天气数据的存储
- 取天气数据的存储
天气数据
存天气
由于天气都是细致到经纬度上的数据,所以存储天气,并且实时更新根据实际需求判断是否可行。
如果需要,则需要一个单独的字典倒表查询的数据库,可由ES、Lucene甚至关系型数据库、Redis完成,前提是服务器的磁盘以及运行空间需要有足够预留。
在消费方拿去天气数据时,同步将天气的经纬度以及数据和当前数据的时效时间进行存储。
时效时间过期,则清空数据
取天气
收集所有天气条件的经纬度
将查询出来的数据,指定放入一个自定义时间的收集桶中;
当桶时间过期,重新进行天气数据的收集。
对数据的划分有两种说法:
一是模糊化经纬度,将相近经纬度的位置都放在一个区域中;这样做,可以非常有效的减少请求天气数据的频率
二是将时间拉长,允许一小时的时效偏差。
不过不管使用那种方式,都无法保证天气数据同时需要爬取的数量;
所以,在进行以上两种方式其一的处理外;
还需要将所有的数据进行分片处理,把爬取所有天气数据的动作分布在一小时内的每个时间段中。
使用预先编排,延时执行的思路。
这样可以有效的控制天气数据爬取的风险
最终的动作:
开启一个每半小时/小时/... 根据需求设定的定时任务,在定时任务中,将当前所有天气条件的经纬度取出。
并将其分组分布在一小时的 15/10/5/...分钟上
当时间在分组片上时,执行天气数据拉取 -> 规则引擎判断 流程
目标值
条件为设备变为某某状态
将设备-某某状态,做成Key进行存储。
当设备—某某状态发生改变时,只需组合Key值去获取有当前条件的场景
然后具体内容具体判断即可
内循环问题
当场景A的执行目标为场景B的执行条件,场景B的执行目标为场景A的执行条件时,触发无限内循环。
根据功能需求,一般有两种考虑方案。
首先得明确,内循环场景是无法避免创建的,除非需求要求无法创建;但是这样对用户使用体验来说很不友好,因为用户并不知道自己所建场景为内循环场景。
所以有两种处理:
- 默认允许创建内循环场景
- 创建时进行当前场景是否为内循环场景的校验,提醒用户
校验内循环
如何校验场景是否为内循环,就是一个处理起来比较繁琐的事
在考虑场景执行场景中,有两种情况:
- A场景执行B场景,B场景的执行目标为A场景指令
- A场景执行目标、条件和B场景互补
不管那种,我们都需要在创建一个新场景时,将执行的动作通过DFS算法搜索把可能包揽的所有指令查询出来。
然后将这样指令作为查询场景的条件
指令集=查询场景条件 创建场景的条件 = 查询场景目标指令
就可以得到与当前创建场景建立内循环的场景。
但是
由于执行条件往往都带有 大于 大于等于 小于等于 小于 等于 等等符号判断式,在查询的时候又要根据对应的值与其区间进行处理。
除此之外,场景也存在与、或运行的执行判断。在获取指令集中,还得考虑指令集中的指令与另外场景的内循环关联。
默认允许创建
允许创建的前提下,一定得保证一件事:系统不可存在影响运行级别的无限循环线程
内循环场景若不进行限制或关闭,一定是一个在主线程管理之外的子线程
考虑出两种处理方式:
- 抑制执行速度
- 关闭内循环流
不管那种方式,都是需要一个判断条件
比如将本次场景触发的条件+值+唯一标识,hash运算后获得唯一码;在规定时间内,如果再次执行当前场景并且唯一码算出来相同,那么就进行 抑制 Sleep ,关闭 Close 动作
但是根据业务需求,有时又允许内循环执行,所以除了抑制和关闭外;
也可以进行限流的思路,将同一个场景的执行次数,在一个时间内限制次数。