Spring集成Elasticsearch自动维护文档设计
Spring集成Elasticsearch自动维护文档设计
使用Elasticsearch的过程中,除了基操中安装、部署、接入Elasticsearch-api慢慢可以孰能生巧外。对于Elasticsearch索引文档的维护一直是令开发头痛的问题,因为除了db数据库中的CRUD操作外,还需要时刻注意增删改操作对Elasticsearch索引文档的影响;
因此作为开发的我们,急需一个框架工具让我们在平时开发中尽可能少的考虑,我现在调用的方法是否会对已经创建的索引发生变更
于是乎结合SpringBoot+Spel表达式设计了一个可以帮助我们无视维护逻辑,仅需提前设置埋点就可以做到自动维护es的索引文档的功能架构
关联项目:https://github.com/LeYunone/spring-es-leyunone
逻辑图
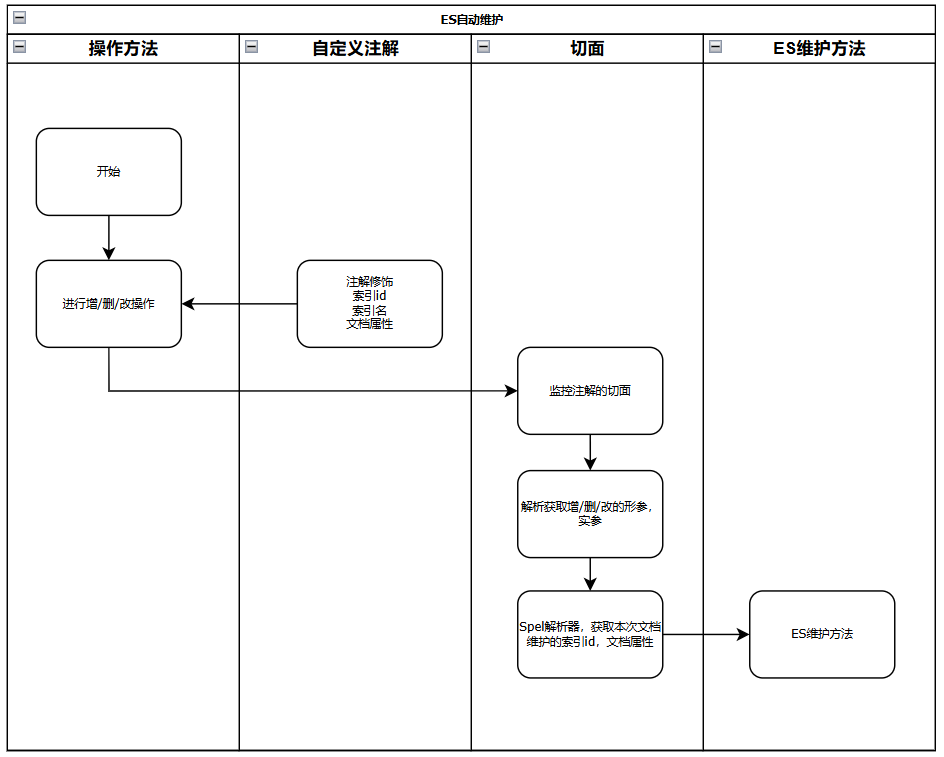
核心思路
注解
我们可以围绕着实际操作数据的方法设置切面埋点,而后通过Spel的特殊解析手段获取我们调用增删改操作方法时的入参用于后续维护文档的方法,最终实现不需要额外的代码维护ES文档的效果;
因此我们需要先定义一个注解,用来配置这个方法调用后对文档的影响是新增/删除/更新,以及文档的配置信息包含:文档名、文档id、关键字对象...
@Retention(RetentionPolicy.RUNTIME)
@Target({ElementType.METHOD})
@Documented
public @interface EsIndexMaintenance {
OperationTypeEnum type();
String indexName();
String indexId();
String[] doc() default {};
String[] docField() default {};
enum OperationTypeEnum {
ADD,
UPDATE,
DELETE,
//更新或插入
SAVE;
}
}
| 属性 | 含义 |
|---|---|
| type | 指定方法对es文档的操作类型 |
| indexName | es文档索引名 |
| indexId | es文档索引id,Spel表达式,获取修饰方法的入参 |
| doc | es文档内容,Spel表达式,获取修饰方法的入参 |
| docField | es文档内容的key,与doc数组下标一一对应 |
将注解修饰在涉及es文档操作的方法上,比方说简单的表单操作中直接设置在dao层方法中,如例:
@EsIndexMaintenance(type = OperationTypeEnum.ADD,
indexName = "test-create",
indexId = "#docTestList.![id]",
doc = {
"#docTestList.![name]",
"#docTestList.![age]"
},
docField = {
"name",
"age"
})
public void createDocs(List<DocTest> docTestList) {
}
其中doc数组中的Spel表达式后续会提到我们改如何解析和定义,因此在定义与使用注解后,要点在于切面中解析表达式部分
切面
见切面:
@Aspect
@Component
public class EsIndexMaintenanceAspect {
private static final DefaultParameterNameDiscoverer PARAMSUTIL = new DefaultParameterNameDiscoverer();
private static final SpelExpressionParser PARSER = new SpelExpressionParser();
@Around("@annotation(esIndexMaintenance))")
public Object esIndex(ProceedingJoinPoint point, EsIndexMaintenance esIndexMaintenance) throws Throwable {
//拿到注解参数
//...String indexIdExpress, String[] docExpress, String[] docFieldNames
//解析方法入参,获取形参名
MethodSignature methodSignature = (MethodSignature) point.getSignature();
Method method = methodSignature.getMethod();
//形参名
String[] argNames = PARAMSUTIL.getParameterNames(method);
//实参值
Object[] args = point.getArgs();
//解析Spel
EvaluationContext context = new StandardEvaluationContext();
for (int i = 0; i < argNames.length; i++) {
context.setVariable(argNames[i], args[i]);
}
//1.通过Spel拿到索引文档id
Expression idExpressMachine = PARSER.parseExpression(indexIdExpress);
Object id = idExpressMachine.getValue(context);
//2.通过Spel拿到doc文档的value
List<Object> docs = new ArrayList<>();
for (String doc : docExpress) {
Expression docExpressMachine = PARSER.parseExpression(doc);
docs.add(docExpressMachine.getValue(context));
}
/**
* 3.组件本次维护索引文档的对象
* 基于文档id值判断:
* -. id为集合时,说明本次为文档的批量操作
* -. id非集合时,说明本次是单个操作
*/
if (Collection.class.isAssignableFrom(id.getClass())) {
//批量操作
List ids = CollectionUtil.newArrayList((Collection) id);
for (int i = 0; i < ids.size(); i++) {
EsDocConstruct esDocConstruct = new EsDocConstruct();
esDocConstruct.setId(ids.get(i));
JSONObject docJson = new JSONObject();
//docs中是文档内容的集合
for (int j = 0; j < docs.size(); j++) {
Collection docValue = (Collection) docs.get(j);
docJson.put(docFieldNames[j], CollectionUtil.newArrayList(docValue).get(i));
}
esDocConstruct.setDoc(docJson);
esConstructs.add(esDocConstruct);
}
} else {
//单点操作
EsDocConstruct esDocConstruct = new EsDocConstruct();
esDocConstruct.setId(id);
JSONObject docJson = new JSONObject();
for (int i = 0; i < docFieldNames.length; i++) {
docJson.put(docFieldNames[i], docs.get(i));
}
esDocConstruct.setDoc(docJson);
esConstructs.add(esDocConstruct);
}
//4. 最终文档维护方法
}
public class EsDocConstruct {
private Object id;
private JSONObject doc;
}
}
这里解释一下Spel的解析与定义,如注解中的使用案例:
当表达式为#docTestList.![id]时,指拿到docTestList属性中的所有id值
当表达式为#XXXXX.![name]时,指拿到XXXXX属性中的所有name值
当表达式为#docTest.name 时,指拿到docTest属性中的name值
当表达式为#id或#ids时,指拿到id和ids值
在这段代码中,我们将方法的形参名和其实参值投入到Spel解析器的上下文中
EvaluationContext context = new StandardEvaluationContext();
for (int i = 0; i < argNames.length; i++) {
context.setVariable(argNames[i], args[i]);
}
当将上述描述表达式投入到解析器中,即可拿到预估的值
更多的Spel使用可见:https://cloud.tencent.com/developer/article/1676200
维护
既然拿到了本次操作维护文档的操作对象,维护起来就很简单了
不管是删除、新增亦或是更新都可以直接拿到批量操作的API:
private boolean xxxxx(String indexName, List<EsDocConstruct> esConstructs) {
try {
BulkRequest request = new BulkRequest();
for (EsDocConstruct esConstruct : esConstructs) {
//新增
request.add(new IndexRequest(indexName).id(esConstruct.getId().toString())
.opType("create").source(esConstruct.getDoc(), XContentType.JSON));
//更新
request.add(new UpdateRequest(indexName, esConstruct.getId().toString()).doc(esConstruct.getDoc(), XContentType.JSON));
//删除
request.add(new DeleteRequest(indexName, esConstruct.getId().toString()));
//保存
request.add(new UpdateRequest(indexName, esConstruct.getId().toString()).upsert(XContentType.JSON).doc(esConstruct.getDoc()));
}
restHighLevelClient.bulk(request, RequestOptions.DEFAULT);
return Boolean.TRUE;
} catch (Exception e) {
logger.error("Elasticsearch#operation, 索引名称:{}, 执行异常:{}", indexName, e);
}
return Boolean.FALSE;
}
查询
后续发现关键字查询方法也可以直接封装成一个非常通用的方法,顺便分享出来这样的封装:
/**
* 搜索方法
* @param query 查询条件
* @param keyWordObject 文档关键字对象
* @param response 查询出来的结果文档
* @param indexName 索引值
* @param <T>
* @return
*/
public <T> EsSearchResultData<T> search(EsSearchQuery query, Class<?> keyWordObject, Class<T> response, String... indexName ) {
SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();
sourceBuilder.size(query.getPageSize());
sourceBuilder.from((query.getPageIndex() - 1) * query.getPageSize());
BoolQueryBuilder queryBuilder = QueryBuilders.boolQuery();
Field[] fields = keyWordObject.getDeclaredFields();
if (StringUtils.isBlank(query.getKeyWord())) {
//空白搜索全部
queryBuilder.must(QueryBuilders.matchAllQuery());
} else {
//组件关键字对象寻找所有字段
queryBuilder.must(QueryBuilders.multiMatchQuery(query.getKeyWord(), Arrays.asList(fields).stream().map(Field::getName).toArray(String[]::new)));
}
sourceBuilder.query(queryBuilder);
// 高亮处理
HighlightBuilder highlightBuilder = new HighlightBuilder();
for (Field field : fields) {
highlightBuilder.field(field.getName());
}
highlightBuilder.requireFieldMatch(false);
highlightBuilder.preTags("<span style='color:red'>");
highlightBuilder.postTags("</span>");
sourceBuilder.highlighter(highlightBuilder);
SearchRequest searchRequest = new SearchRequest(indexName);
searchRequest.source(sourceBuilder);
SearchResponse search = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
return convertSearchResult(search, response);
}
public <T> EsSearchResultData<T> convertSearchResult(SearchResponse searchResponse, Class<T> response) {
if (ObjectUtil.isNull(searchResponse)) {
return EsSearchResultData.emptyResult();
}
SearchHits hits = searchResponse.getHits();
EsSearchResultData<T> esSearchResultData = new EsSearchResultData<>();
esSearchResultData.setTotal(hits.getTotalHits().value);
List<T> result = new ArrayList<>();
esSearchResultData.setRecords(result);
for (SearchHit hit : hits.getHits()) {
//json字符串
T o = JSONObject.parseObject(hit.getSourceAsString(), response);
Map<String, HighlightField> highlightFields = hit.getHighlightFields();
if (CollectionUtil.isNotEmpty(highlightFields)) {
//高亮匹配到的第一个字段
o.setDisplayText(highlightFields.values().iterator().next().getFragments()[0].string());
}
result.add(o);
}
return esSearchResultData;
}
public class EsSearchResultData<T> {
private Long total = 0L;
private List<T> records = new ArrayList<>();
private String hitDisplayText;
}
总结
适用于绝大多数表单型功能的文档维护,解放我们对es文档维护的思考;
不过并没有考虑到es文档API调用的弊端,一切都是为了简单。因此除开Spel解析部分,维护ES的方法推荐使用mq或是其他的异步手段