数据库增量同步模型方案
数据库增量同步模型方案
数据库增量同步:数据库A,数据库B;B使用增删改使其数据库中的数据与数据库A一致,这就是数据库增量同步。
背景:做项目的时候,由于不可抗因素的影响,导致某个数据库C在本项目A中无法直接访问;只能通过建立一个中间数据库B,然后由B数据库同步数据库C中的数据【简单的说就是数据库C所在的服务器开通一个端口给数据库B所在的服务器】,A则读取B中的数据,A >< B >< C。
方案实现
宏观的看,实现起来很简单。
如下,我将通过一个表的同步演说思路:
先准备以下几点:
- 两个定时器,一个15秒执行一次;一个一天某个凌晨点执行一次;
- 两个标识,一个记录最后新增的时间,一个记录最后修改的时间
- 原数据库中,需要同步的表中一定有创建时间,以及更新时间
定时器1 15秒
在这个定时器中,实现以下逻辑:
数据库B中,取该表上一次同步的最新新增时间和最新更新时间
根据最新的时间,查询数据库C的比已经记录时间更早的新数据
where ((CREATE_DATE=#{lastUpdateTime} OR MODI_DATE=#{lastUpdateTime}) AND CREATE_DATE >=#{lastCreateTime}) OR (CREATE_DATE>#{lastUpdateTime} OR MODI_DATE>#{lastUpdateTime})将读到的数据覆盖写入数据B
记录本次读取数据的最早创建时间以及更新的最新更新时间
定时器 一天一次
在这个定时器中,实现以下逻辑:
- 根据创建时间和更新时间读取数据库C今天的所有数据
- 根据创建时间和更新时间读取数据库B今天的所有数据
- 对比数据C与数据B读取到的数据,所有C读到12356,C读到123456,则说明4被数据C删除,则进行清除操作
- 根据主键过滤出删除的数据,然后在数据B中删除
总结
用白话语来说,一个定时器用来读数据库C的数据,然后写到数据B,记录每一次最新的更新时间与创建时间;
一个定时器用来清除,根据主键对比数据库C与数据库B的数据差异,将数据库B中多余数据删除
实践
基于Mybatis-plus+SpringBoot特性+XXLJOb的顶级同步模型
项目Git地址 可直接享用
数据库之间进行数据同步思路简单,但是如果单位是每一张表,那么读->写,这种繁琐的操作,对于每一张表都是重复性的操作;所以我们可用通过SpringBoot+mybatis以及JAVA的特性,将所有表的读->写操作抽成一个模型
第一步
准备好每张表对应的entry实体类,并且!,使用@TableName以及@TableId和@TableField,标注实体类对应表的名称以及主键;
@TableName("INVTB")
public class InvtbDO extends BaseModel implements Serializable {
private static final long serialVersionUID = 137292315565013474L;
/**
* 单别
*/
@TableId("id")
private String id;
/**
* 品号
*/
@TableField("name")
private String name;
/**
* 创建时间
*/
@TableField("CREATE_DATE")
private String createDate;
/**
* 修改者
*/
@TableField("MODIFIER")
private String modifier;
/**
* 修改时间
*/
@TableField("MODI_DATE")
private String modiDate;
}
第二步
通过 继承 ApplicationListener 类,以及IOC加载顺序,将自定义的BeanDefinitionBuilder注入到容器中;
而这个BeanDefinitionBuilder则是数据同步模型的核心,
我们定义一个基类目标数据库服务,以及基类源数据库服务;
服务中存储,每一张表的表名,主键,以及表对应的BaseMapper基类;

第三步
建立Dao层的基类DB服务,使用加载出的tableName,promarkeys,可以拼接出所有表的更新或新增语句、删除语句、最新时间语句等等等等;
这里最好是看项目代码


第四步
最终通过已经自动装配好的所有表的SourceService、TargetService、BaseSourceDao、BaseTargetDao,通过定时任务设置好的参数,来进行各自表的读、写、删除等同步操作;互不干涉。
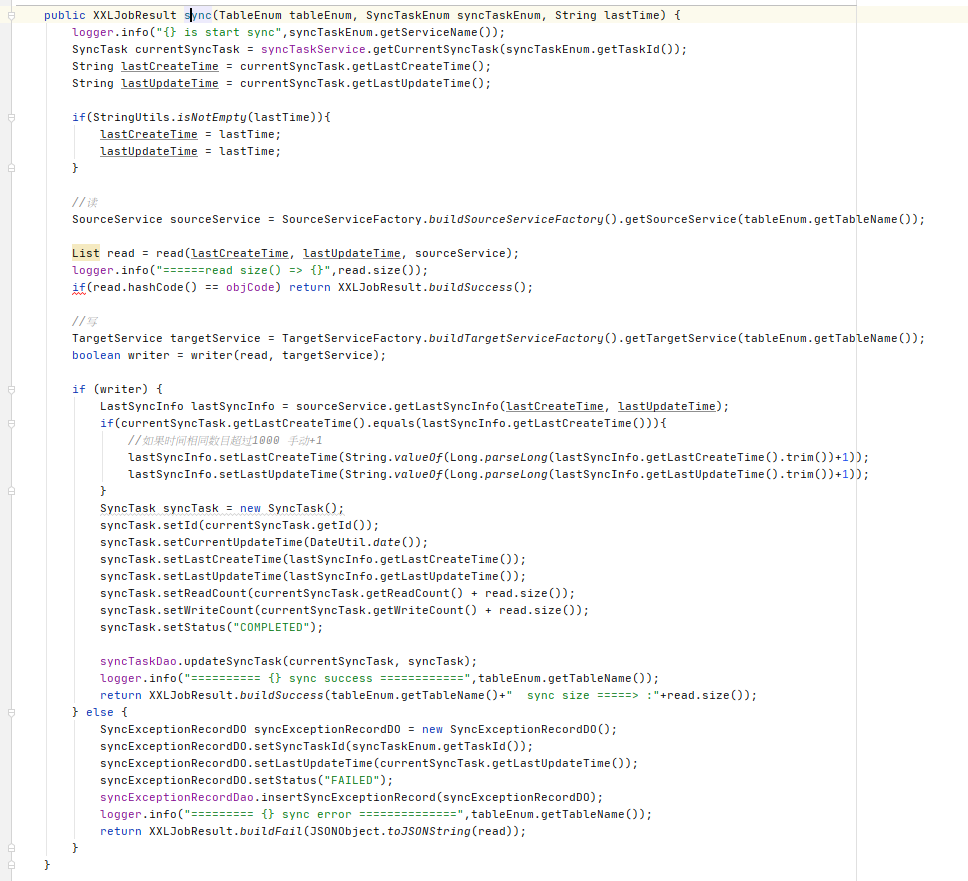
总结
根据SpringBoot的IOC、启动的特性,灵活的将每一张需要同步的表自动封装、拼接、整理成一个个可直接使用的服务类;以及MyBatis的xml中#{} 拼接语句的可行性,完成了这一以前从没想过能成功的案例;
所以说,一个看起来很厉害、很顶层的项目,一定是以某些技术、某些框架或者工具的底层特性为理论,来一步一步搭建成功;