高效上传下载文件
高效上传下载文件-后端处理模式
之前有做一个网盘,采取的是非常原始的基于File-response,文件流形式一对一传输的模式。所以导致在传输一些大文件时,无法实时看到进度,并且总会有各种意外发生:断网、手抖关掉页面等,所以总要想办法解决这个大麻烦嘛😰
文件传输
文件传输在一个简单的Client-Server中,不使用FTP连接文件服务时,由以下行程完成:
- 包装MultipartFile发送给Server。
- Server接收,包装Server侧保存文件路径
- MultipartFile通过IO流形式,写到Server侧
- 结束
如果是一张图片,一个小至100KB的文档,那么这个流程可以说是毫无破绽的。 但是作为网盘,肯定有大文件、超大文件、传一半等等这些“极端”的场景存在。 那么我们则需要根据这些个极端场景,定制出属于他们的高效场景出来。
场景处理
在信息传输中,如果实时的保证文件的全传输的可靠,无论是使用Redis或是数据库或是其他中间件,消耗的性能及空间在一次传输中极为庞大。 所以我们需要将这个大型文件,拆分成一个个在系统中进行消耗可以忽略不计的小文件。 这样做的好处有:
- 一次传输拆分成多次传输,增加了容错性。
- 前台展示,可以根据小文件的传输成功数目,动态变化整个文件的传输进度
- 小文件=分片,通过客户端与服务端定义分片规则,可以达到一次文件,多次上传,高效处理的模式。
那么跟着这三点我们可以得到常见的一个名称**:分片上传**
分片上传
在第三点我们提到:小文件 = 分片。 倘若我们有一个1G = 1024MB的文件,通过量级计算,
1024/5 = 205
我们将一个文件,将这个文件流或二进制数组的存储模式,分成205个大小为5MB的小文件。 每个小文件都是独立的,没有任何的文件属性,仅带着原始文件被偏移的二进制数据以及文件信息。 再通过前端操作,并发的形式传给服务端。 这时候,后端接收的,至少是一份这样的数据:

后端接收到了一份小文件后,第一时间不是进行存储,而是应该进行安全性的校验:
- 这个小文件是否是大文件的分片
- 我有没有余力IO通过,处理
- 小文件是否为空
而校验的核心,是基于上传文件的一个前置条件的**:大文件的特征编码** 聊到这,也正好可以解决秒传的一个业务场景
秒传
在一般上传功能中,在正式上传文件前,应该对本次操作进行一些列的判断或申请。 有些可以在前端完成,比如文件的类型、大小、名字等等。 但有一些只能在后端处理,比如上传用户的合法、文件服务器的可用及容量等等。 不管是哪方面的处理,对一个文件而言,都应该有一个标识码,去绑定这个文件。无论这个文件如何变化,只要文件本身内容不变,那么我们都可以通过这个标识码定位到这个文件,像文件拥有一张身份证一样。 根据这个理解,可以非常快速的画出秒传的流程。
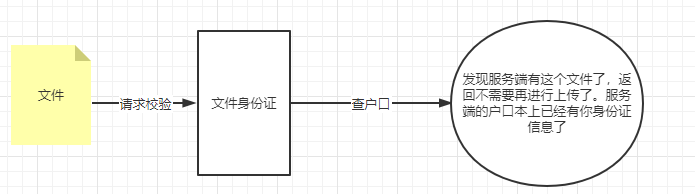
身份证可以是和文件信息绑定的,随机生成的UUID。 但更推荐,基于文件流通道解析出来的MD5
MappedByteBuffer byteBuffer = in.getChannel().map(FileChannel.MapMode.READ_ONLY, 0, file.length());
MessageDigest md5 = MessageDigest.getInstance("MD5");
md5.update(byteBuffer);
BigInteger bi = new BigInteger(1, md5.digest());
String md5str= bi.toString(16);
当然,发现服务端有了这个文件后,是要进行拷贝呢还是啥,纯由业务控制。
合并
在确定这个文件是需要分片,并且已经接收到各类小文件后,我们需要准备的是:
- 设置一个唯一路径,当作所有小文件的虚拟目录
- 持续接收,直到发现sliceIndex = sliceAll,最后一个分片写入到虚拟目录中。
- 合并虚拟目录的所有文件,导出到目标文件中
- 清理“后事”
作为程序员,有注释的代码比文字更赏心悦目,所以我直接贴代码了,代码 = 思路
public DataResponse sliceUpload(UpFileDTO upFileDTO) {
String userId = upFileDTO.getUserId();
//文件key
String fileKey = upFileDTO.getFileKey();
//本次文件的MD5码
String fileMD5Value = cacheExe.getFileMD5Value(userId, fileKey);
AssertUtil.isFalse(StrUtil.isBlank(fileMD5Value), ErrorEnum.FILE_UPLOAD_FILE.getName());
//获得分片文件存储的临时目录
String tempPath = this.resoleSliceTempPath(fileMD5Value);
AssertUtil.isFalse(StrUtil.isBlank(tempPath), ErrorEnum.FILE_UPLOAD_FILE.getName());
//开始进行切片化上传
File sliceFile = new File(tempPath + upFileDTO.getSliceIndex());
//如果这个片在历史中已经完成,则跳过
if (!sliceFile.exists()) {
FileOutputStream fos = null;
InputStream inputStream = null;
try {
fos = new FileOutputStream(sliceFile);
//本次上传文件
inputStream = upFileDTO.getFile().getInputStream();
//写入文件
IOUtils.copy(inputStream, fos);
//判断本请求是否是最后的分片,如果是最后的分片则进行合并
Integer size = sliceFile.getParentFile().listFiles().length;
if (size.equals(upFileDTO.getSliceAll())) {
//合并文件
String filePath = this.mergeSliceFile(tempPath, upFileDTO.getFileName());
//保存文件信息
String saveId = FileInfoE.queryInstance().setFilePath(filePath).
setFileSize(upFileDTO.getFileSize()).setFileType(upFileDTO.getFileType())
.setName(upFileDTO.getFileName())
.setSaveDt(StrUtil.isEmpty(upFileDTO.getSaveTime()) ? "永久保存" : upFileDTO.getSaveTime()).save();
//加载到用户文件列表上
FileUserE.queryInstance().setUserId(userId).setFileId(saveId).save();
//计算用户新内存
FileUpLogCO fileUpLogCO = FileUpLogE.queryInstance().setUserId(userId).selectOne();
AssertUtil.isFalse(ObjectUtil.isEmpty(fileUpLogCO),ErrorEnum.FILE_UPLOAD_FILE.getName());
FileUpLogE.queryInstance().setId(fileUpLogCO.getId())
.setUpFileTotalSize(fileUpLogCO.getUpFileTotalSize()+upFileDTO.getFileSize()).update();
//上传完成,删除临时目录
this.deleteSliceTemp(tempPath);
//删除成功,清除redis
cacheExe.clearFileMD5(userId,fileKey);
//开启计时保存功能
if(StrUtil.isNotBlank(upFileDTO.getSaveTime())){
cacheExe.setSaveTimeFileCache(saveId,userId,upFileDTO.getSaveTime());
}
}
} catch (Exception e) {
if (fos != null) {
try {
fos.close();
} catch (IOException ioException) {
ioException.printStackTrace();
}
}
if (inputStream != null) {
try {
inputStream.close();
} catch (IOException ioException) {
ioException.printStackTrace();
}
}
}
}
return DataResponse.buildSuccess();
}
代码:https://github.com/LeYunone/leyuna-disk/blob/master/disk-core/src/main/java/xyz/leyuna/disk/service/file/FileService.java 其中有很多逻辑是我的数据库业务,或redis业务代码,但是在网盘应用中大多都是通用的,看看也无妨。
断点续传
断点续传,适合对下载功能处理。 但是要注意,由于文件是保存在服务端的,所以断点续传是基于客户端稳定的前提下完成。 大致逻辑和分片相似:
- 客户端请求断点续传,将临时/虚拟目录发给服务端。
- 服务端接收文件,并且通过定义起始值、偏移量、总值,动态的写出文件。
- 实时更新/断开时返回,将起始值、偏移量、总值、文件信息保存在客户端,并且将未写完的文件暂存在客户端指定目录。
看思路,很明显,断点下载非常考验客户端这边的合法及可用的。 比如用户将半下载的文件删除,清理返回信息、时间长久等等 都会导致断点下载不稳定的出现异常。 
小文件处理
以上,不管是断点续传还是分片。 都是高效处理、完美体验,解决文件上传的一些难题。 但是小文件也是有一些自己的处理场景的。 在存储图片、小文档、微小文件时,我们是否可以考虑将这些文件转换成Base64编码,存在第三媒介中呢。 因为即使是再小的文件,在进行文件上传或下载时,都会有IO流: 打开输出流 - 打开输入流 - 关闭输出流 - 关闭输入流 这样频繁的操作,虽说不占用性能,但如果我们将这些极小:几十KB或者1MB,自定义小。存在redis中,是否可以更快速的读、写呢。
总结
本文提出的只是文件上传时,分片、断点的一部分场景。其实在实际生产中,遇到的问题原比网络中理论的要多。比如文件太大,最后分片等待太久,且并发量高,意味着占了一个线程资源不动,并且‘死锁’在这。还比如,文件上传的数据丢失、乱码,数据损坏等待诸多问题。 后端在这些场景中,能做的一是优化、二是更合法的规则校验、三是提前预知。所以说下载场景是需要前、后端高强度配合的业务。